Introduction
NVLM est un modèle de langage multimodal à la pointe de la technologie.
Qu'est-ce que NVLM ?
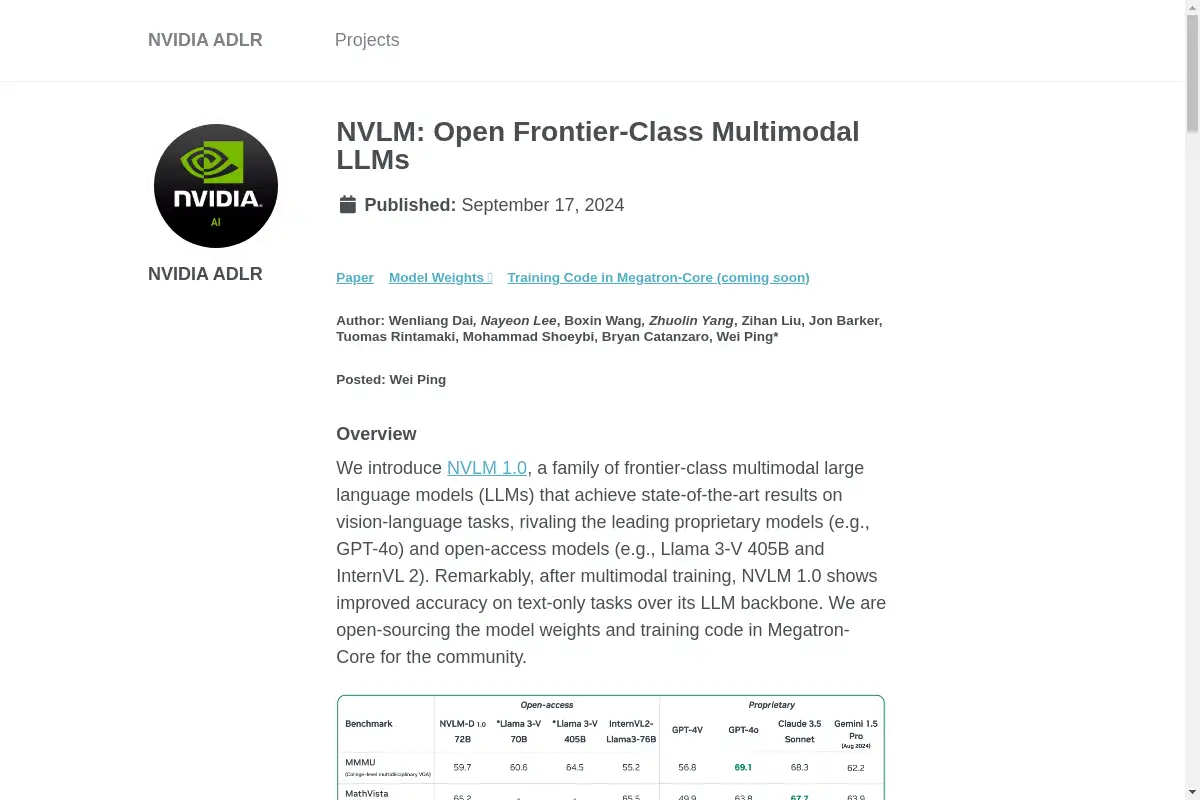
NVLM, ou NVLM 1.0, est une famille de modèles de langage multimodaux à la pointe de la technologie développés par NVIDIA. Il excelle dans les tâches de vision-langage et améliore même les performances sur les tâches uniquement textuelles par rapport à son architecture de modèle de langage (LLM). Avec une architecture robuste et une formation extensive, NVLM rivalise avec les modèles propriétaires de premier plan comme GPT-4o et les alternatives en accès libre telles que Llama 3-V.
Caractéristiques principales de NVLM
Capacités multimodales avancées
NVLM intègre texte, images et raisonnement, lui permettant d'exécuter des tâches complexes nécessitant la compréhension à la fois d'informations visuelles et textuelles.
Performance améliorée en texte seul
Contrairement à d'autres modèles qui subissent une baisse de performance dans les tâches uniquement textuelles après une formation multimodale, NVLM montre des améliorations significatives, notamment dans les benchmarks mathématiques et de codage.
Conception architecturale novatrice
Le modèle utilise une architecture unique qui combine les forces de différentes approches multimodales, améliorant l'efficacité de la formation et les capacités de raisonnement.
Cas d'utilisation de NVLM
Génération de descriptions d'images
Les utilisateurs peuvent entrer des images, et NVLM génère des descriptions détaillées, capturant les nuances et le contexte.
OCR et reconnaissance de texte
Le modèle peut effectuer avec précision la reconnaissance optique de caractères, le rendant utile pour l'extraction de texte à partir d'images.
Raisonnement mathématique et codage
NVLM peut résoudre des problèmes mathématiques et écrire du code basé sur des indices visuels comme des tableaux et du pseudocode.
Comment utiliser NVLM ?
Pour utiliser NVLM, les individus peuvent accéder aux poids du modèle et au code de formation disponibles sur Hugging Face. Les utilisateurs doivent configurer un environnement compatible avec Megatron-Core et suivre les instructions fournies pour mettre en œuvre le modèle pour diverses tâches.
Public cible de NVLM
- Chercheurs en IA et apprentissage automatique
- Développeurs travaillant sur des applications multimodales
- Éducateurs à la recherche d'outils avancés pour l'enseignement
- Entreprises souhaitant intégrer l'IA dans leurs opérations
NVLM est-il gratuit ?
Oui, NVLM est open source, offrant un accès gratuit à ses poids de modèle et à son code de formation pour la communauté. Cependant, les utilisateurs doivent prendre en compte le coût des ressources informatiques nécessaires pour faire fonctionner le modèle efficacement.
Questions fréquentes sur NVLM
Quels sont les principaux avantages de NVLM par rapport à d'autres modèles ?
NVLM montre une performance supérieure tant sur les tâches de vision-langage que sur les tâches uniquement textuelles, le rendant polyvalent pour diverses applications.
Comment puis-je accéder au modèle NVLM ?
Vous pouvez accéder aux poids du modèle et au code de formation via la plateforme de Hugging Face.
Quel type de tâches NVLM peut-il gérer ?
NVLM peut effectuer une gamme de tâches, y compris la description d'images, l'OCR, le raisonnement mathématique et le codage.
Tags de NVLM
Multimodal, Modèle de Langage de Grande Taille, IA, Vision-Language, Open Source, NVIDIA.