什么是SadTalker:学习为风格化的音频驱动单人图像说话面部动画生成逼真的3D运动系数?
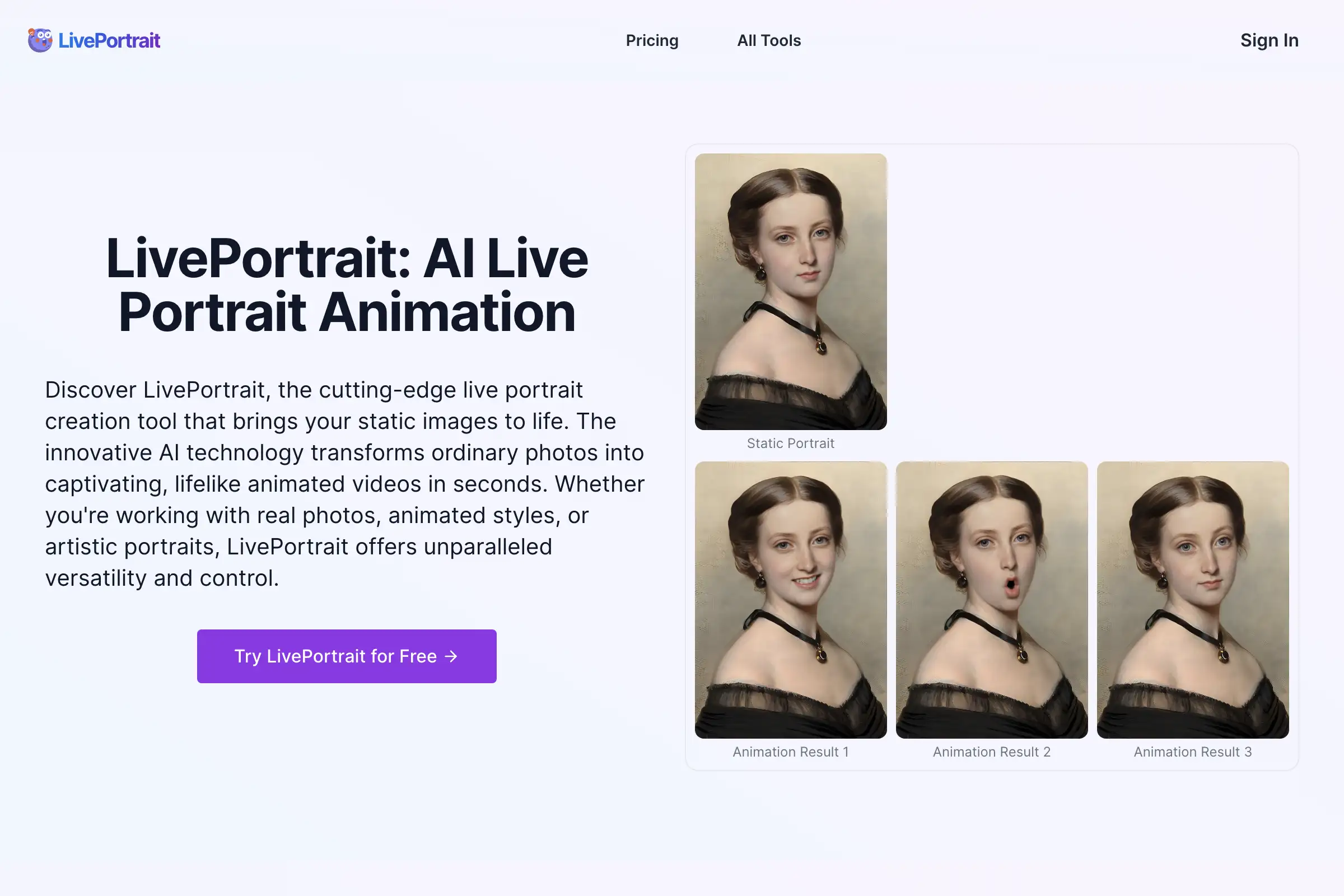
什么是SadTalker?SadTalker是一种技术,它为风格化的音频驱动单人图像说话面部动画生成逼真的3D运动系数,解决了头部运动不自然、表情扭曲和身份改变等问题。
SadTalker:学习为风格化的音频驱动单人图像说话面部动画生成逼真的3D运动系数的用例?
SadTalker的用例包括用不同语言生成说话头部视频、用不同语言唱歌、可控的眨眼以及在各种数据集上的比较。
适用于SadTalker:学习为风格化的音频驱动单人图像说话面部动画生成逼真的3D运动系数的人群?
SadTalker的目标受众包括计算机视觉、人工智能和动画领域的研究人员、开发者和专业人士。
SadTalker:学习为风格化的音频驱动单人图像说话面部动画生成逼真的3D运动系数是否免费?
关于SadTalker是否免费的信息在给定的上下文中没有提供。