DeepSeek V3.2-推理与Agent能力的双重进化

DeepSeek昨天发布了V3.2,同时还有个Speciale版本。这次更新和之前的小版本迭代不太一样,重点放在了两个方向:推理能力和Agent场景。看完技术报告,我觉得有几个点值得聊聊。
先说结论:V3.2在数学、编程这些需要深度推理的任务上已经能跟GPT-5打个平手,Speciale版本甚至在IMO、IOI这种顶级竞赛中达到了金牌水平。更关键的是,模型完全开源。
长文本处理的效率问题解决了
V3.2最核心的改动是注意力机制。传统Transformer在处理长文本时有个老大难问题:计算复杂度是O(L²),上下文越长,算力消耗呈平方级增长。这直接影响推理速度和成本。
DeepSeek的方案叫DSA(DeepSeek Sparse Attention)。原理不复杂:用一个轻量级的indexer快速筛选出每个token最需要关注的k个token,然后只对这k个token做注意力计算。复杂度直接从O(L²)降到O(Lk)。
indexer本身的计算开销很小,只用少量的attention heads,而且可以用FP8精度跑,所以整体效率提升明显。官方给的数据显示,在H800集群上处理128K上下文时,V3.2的token成本比上一代低了不少,prefilling阶段尤其明显。
这个改进对实际使用的影响很直接:长文档分析、大规模代码库处理这些场景下,推理速度更快,成本更低。
- BrowseComp: 51.4% (不用context management),67.6% (用了context management策略)
强化学习投入加大
V3.2在后训练阶段的计算投入超过了预训练成本的10%。这个比例在开源模型里不算常见。
Tool Use:
他们用的还是GRPO算法,但做了几个工程优化来保证大规模训练的稳定性。比如修正了KL散度的估计方式,避免梯度不稳定;对off-policy的序列做mask,防止policy偏离太大;保持训练和推理时MoE模型的expert路由一致。这些看起来是细节,但在大规模RL训练中都很关键。
- MCP-Universal: 45.9%
从结果看,随着RL训练时长增加,模型在复杂推理任务上的表现确实在持续提升。这也验证了一个趋势:推理能力的提升越来越依赖后训练阶段的计算投入。
Agent能力的突破
V3.2是DeepSeek第一个在工具调用中集成推理能力的模型。这个听起来简单,实现起来有不少挑战。
- Summary: 超出80%上下文时总结已有轨迹,重新开始
核心问题是:如何让模型在使用工具的同时保持深度思考?DeepSeek的方案是先通过精心设计的system prompt让模型学会在推理过程中调用工具,然后大规模合成训练数据。
数据合成这块做得比较扎实。他们构建了1800多个合成环境,生成了85000个复杂任务:
Search Agent:从网上采样长尾知识点,生成问答对,然后用搜索工具验证答案正确性。这样保证了数据质量。
Discard-all效率更高,准确率能到67.6%,步数还更少。
Code Agent:从GitHub挖了数万个issue-PR对,自动搭建可执行环境。筛选标准很严:必须有明确的bug描述、可验证的测试用例、能跑通的修复方案。覆盖了Python、Java、JavaScript、C/C++、Go、PHP等主流语言。
General Agent:完全合成的环境。比如旅行规划任务,先生成相关数据库,再合成一套专用工具函数,最后生成任务和自动验证函数。验证函数的设计很巧妙:任务本身搜索空间很大(比如要满足多个约束条件),但验证起来很简单(check一遍约束就行)。
这些合成数据不是凑数的。他们做了消融实验:让GPT-5、Gemini 3.0 Pro这些顶级模型跑了50个合成任务,pass@1只有约五到六成。DeepSeek-V3.2-Exp(生成数据的base模型)只有约一成。说明任务确实有难度。
- Claude Sonnet 4.5: 34%
更重要的是泛化能力。拿V3.2的SFT checkpoint只在合成数据上做RL,在真实benchmark上也有明显提升。这证明合成环境和真实场景之间的gap不大。
实际表现怎么样
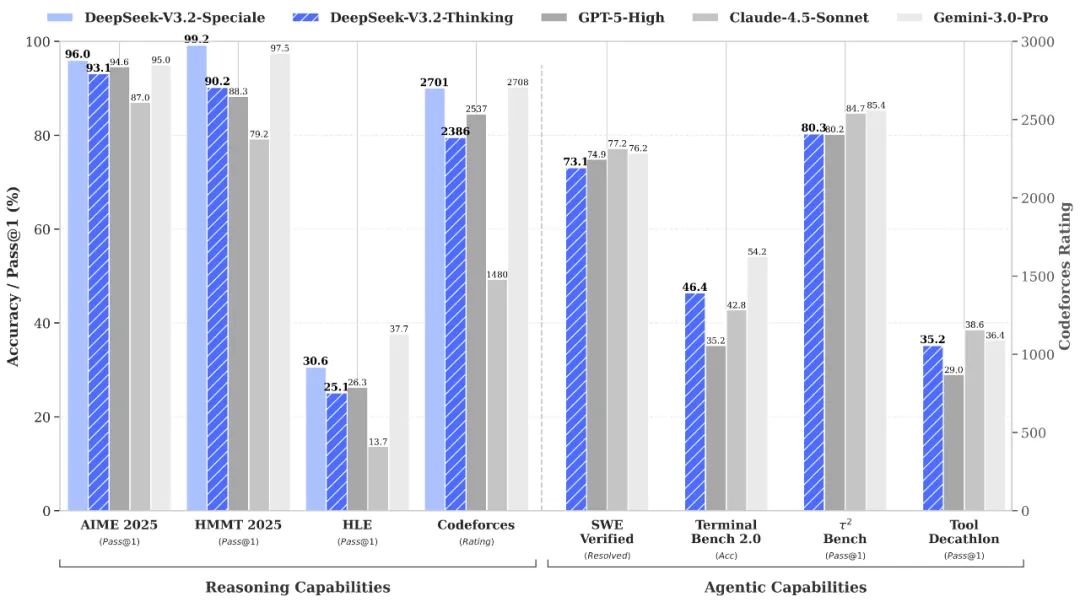
数学和编程任务上,V3.2基本对齐GPT-5-High:AIME 2025准确率93.1%(GPT-5是94.6%),LiveCodeBench是83.3%(GPT-5是84.5%),Codeforces rating 2386(GPT-5是2537)。
Speciale版本的数据更亮眼:AIME 96%,LiveCodeBench 88.7%,Codeforces rating 2701。在IMO 2025拿了35分(满分42),IOI 2025得了492分(满分600),ICPC世界总决赛解出7道题,都是金牌水平。
但token效率是个问题。Speciale在AIME上要用约2万token才能达到96%准确率,Gemini 3.0 Pro用15K token就能到95%。这就是长推理的代价——思考得更深,但也更啰嗦。
V3.2与GPT-5、Gemini 3.0 Pro、Claude Sonnet 4.5在多项任务上的对比
Agent相关的测试中,V3.2明显缩小了开源和闭源的差距。SWE-Verified(实际代码仓库的bug修复)73.1%,接近GPT-5的74.9%。SWE-Multilingual(多语言代码修复)70.2%,甚至超过GPT-5的55.3%。
工具调用方面,τ²-bench 80.3%,MCP-Universal 45.9%,Tool-Decathlon 35.2%。虽然还不如Gemini 3.0 Pro这种顶级闭源模型,但考虑到这是开源模型,已经很不错了。
V3.2支持在工具调用中使用thinking模式。文档链接:https://api-docs.deepseek.com/guides/thinking\_mode
有个小问题:V3.2在使用工具时经常做冗余的自我验证,导致对话轨迹很长,容易超出128K限制。DeepSeek测试了几种context management策略(Summary、Discard-75%、Discard-all),能缓解但还有优化空间。
怎么用
API方式:
V3.2的API调用和之前的V3.2-Exp一样,直接用就行。
Speciale用的是临时endpoint:https://api.deepseek.com/v3.2_speciale_expires_on_20251215,价格跟V3.2相同,但不支持工具调用,只能用到12月15日。主要是给研究者做评测用的。
V3.2支持在工具调用中开启thinking模式。需要注意的是,如果你用Terminus这类通过user message模拟工具交互的框架,thinking的效果会打折扣,因为V3.2在每次user message时会清除推理历史。这种情况建议用non-thinking模式。
开源模型:
两个版本都在HuggingFace上:
V3.2在推理和Agent能力上的进步是比较明显的,特别是在开源模型的context下。但和Gemini 3.0 Pro这样的顶级闭源模型比,还是有差距。
DeepSeek在论文里也承认了几个问题:
适合什么场景
V3.2比较适合这几类需求:
需要强推理能力,但不想依赖闭源API的项目。V3.2在数学、编程、逻辑推理这些任务上已经接近GPT-5水平,而且完全开源。
对于开发者来说,V3.2的意义可能不只是"又一个新模型"。它在某些测试中已经能跟GPT-5持平,而Speciale版本甚至在数学和编程竞赛中拿到了金牌水平的成绩。更关键的是,这些能力都是开源的。
Agent应用,特别是代码相关的。SWE-bench的成绩证明它在实际代码仓库中修bug的能力不错。如果你在做coding assistant、自动化测试、代码审查这类工具,V3.2是个靠谱的选择。
多步骤规划和复杂工具调用场景。虽然在某些benchmark上还不如顶级闭源模型,但V3.2能在工具调用过程中保持推理能力,这在开源模型里是首次实现。
如果你对token消耗不敏感,或者任务本身就需要深度推理(比如数学证明、算法竞赛、复杂系统设计),Speciale会是更好的选择。
还有哪些不足
DeepSeek在论文里也坦诚地提到了几个限制:
知识覆盖面不如顶级闭源模型。这是预训练FLOPs少导致的,只能靠增加预训练计算量来补。
token效率有待提升。V3.2通常需要输出更长的推理链才能达到相同质量,在生产环境中这意味着更高的latency和成本。
复杂任务上还是有差距。虽然在部分测试中接近GPT-5,但在某些需要世界知识和常识推理结合的任务上,还不如Gemini 3.0 Pro这种顶级模型。
从我的观察看,V3.2的发布让开源模型在推理和Agent领域又往前走了一步。虽然和最顶级的闭源模型比还有距离,但至少在不少实际应用场景中已经够用了。对于想用开源方案构建AI应用的开发者来说,这是个不错的选择。
引用
https://api-docs.deepseek.com/news/news251201
https://x.com/deepseek_ai/status/1972604768309871061
https://t.co/7EyydyNuG0
发表评论
- No comments yet.
推荐的AI工具
精心选择的AI工具来改善您的工作,学习和生活效率。
相关文章

2025年11月14日,OpenAI正式开启ChatGPT群聊功能试点,标志着AI从个人助手迈向团队协作伙伴的重大转折
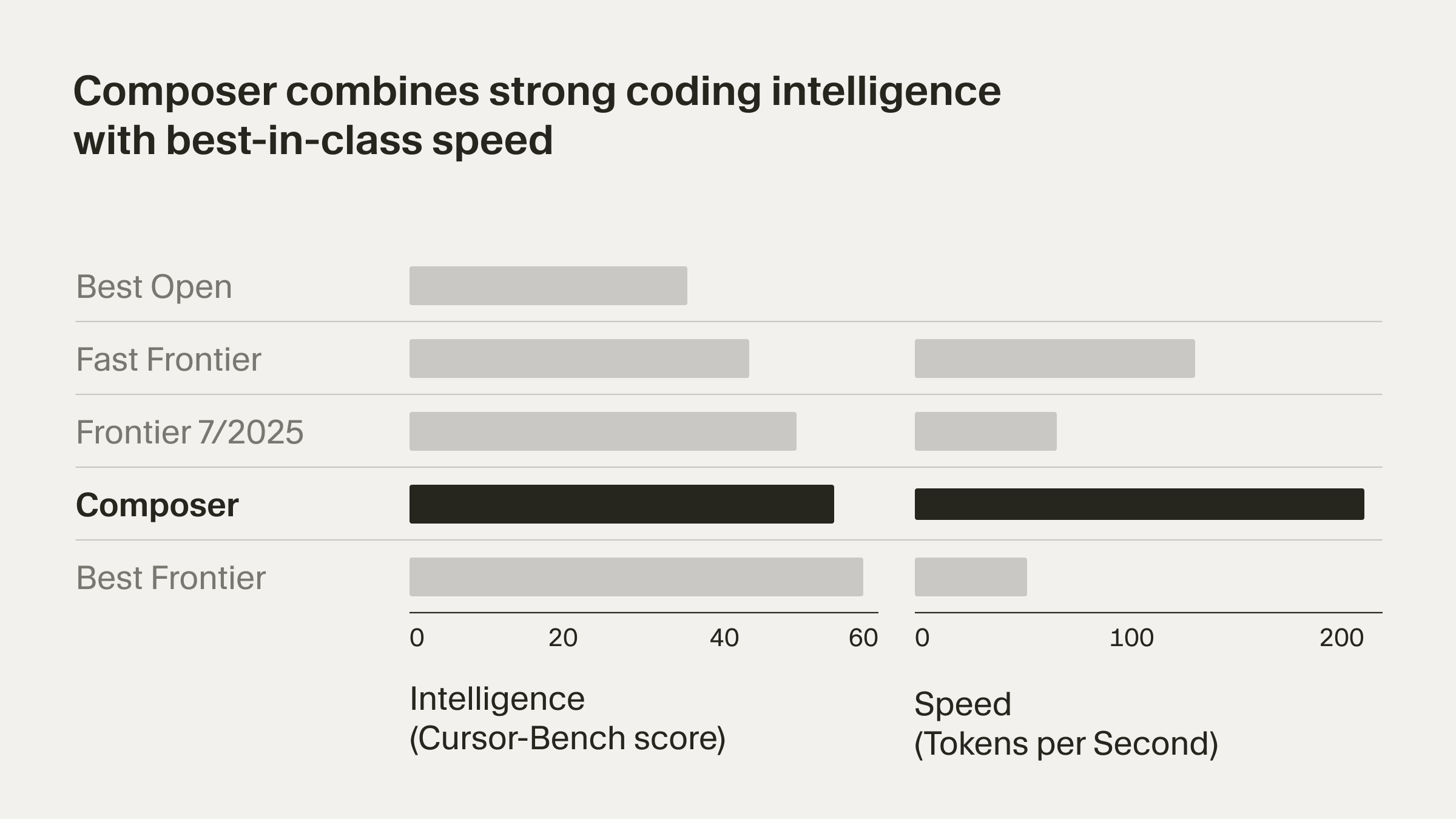
Cursor正式迈入2.0时代!其首个自研编程智能体模型Composer将响应速度提升4倍,更颠覆性地支持最多8个AI智能体并行协作。从此,你不再是代码的“打字员”,而是项目的“总指挥”。