DeepSeekMath-V2:迈向自我验证的数学推理


数学推理正在从"黑盒"走向"可验证"——DeepSeekMath-V2试图让AI不仅会解题,更懂得如何验证推理严谨性
数学竞赛解题领域迎来新进展。2025年11月27日,DeepSeek-AI团队正式发布DeepSeekMath-V2,这个基于671B参数MoE架构的模型在IMO 2025中拿下5道题(金牌水平),Putnam 2024取得118/120分(超越人类历史最高),CMO 2024获得金牌成绩。但真正值得关注的不是这些分数本身,而是它背后实现的技术路径——一套完整的"自验证机制"。
过去,AI解数学题像黑盒:给出答案,但不知道推理过程是否严密。DeepSeekMath-V2尝试突破这个限制,让模型既能生成解题步骤,也能判断每一步是否正确。这种"生成-验证"双循环机制,可能会改变AI处理复杂推理任务的方式。
1 核心创新:从"结果导向"到"过程验证"
传统数学推理模型面临一个矛盾:训练时依赖答案反馈,推理时缺乏过程监督。GPT-4o、Claude 3.5这类模型在遇到难题时往往"跳步"——中间推导不完整,直接给出结论。即便答案正确,推理链也可能有漏洞。人类评委很难判断这种解法是真懂还是"碰运气"。
DeepSeekMath-V2提出一个解决方案:让AI学会"自我审核"。具体做法是训练两个神经网络——生成器负责解题,验证器负责检查。生成器每写一步推导,验证器立即判断"这步对不对"。如果验证器说"错了",生成器回退重来。如果说"对了",继续下一步。
这套机制避免了传统方法的盲目搜索。过去的"穷举法"需要生成几十种解法再挑最优,计算成本极高。DeepSeekMath-V2的验证器可以在推理过程中就淘汰错误路径,把计算资源集中在靠谱方向上。实测数据显示,在Putnam 2024的120分满分题中,模型拿到118分,错误率仅1.7%。
2 技术架构:构建自验证系统的四大支柱
2.1 双模型协同系统
系统核心是两个独立训练的网络。生成器基于DeepSeek-V3.2-Exp-Base(671B参数的MoE架构,单次推理激活37B参数),负责输出解题步骤;验证器同样基于671B MoE模型,但训练目标不同——判断给定步骤的正确性。两者交替工作:生成器提出假设,验证器打分;低分假设被丢弃,高分假设被保留并继续扩展。
2.2 元验证机制 (Meta-Verification)
验证器本身也可能出错。DeepSeek团队引入"元验证器"来校准验证器判断。具体做法:收集验证器的历史评分和真实对错数据,训练一个轻量级元模型预测"验证器这次判断可信度多高"。元验证器将原始验证器的准确率从0.85提升到0.96,意味着系统误判率降低73%。
2.3 自验证增强推理
这是"生成-验证"循环的算法实现。每一步推理都对应一个决策树节点,验证器给每个节点打分(0-1之间)。系统优先扩展高分节点,放弃低分分支。与蒙特卡罗树搜索(MCTS)不同,这套方法不需要完整模拟到终点——验证器在中间步骤就能判断"此路不通",大幅减少无效计算。
2.4 验证计算扩展 (Scaling Verification Compute)
DeepSeek团队发现一个规律:增加验证环节的计算量,收益比增加生成环节更明显。传统"穷举法"让生成器输出1000个解,再挑最优;他们的方法是让生成器输出100个解,但每个解经过10轮验证筛选。实验显示后者在Putnam 2024中正确率高4.2个百分点,耗时却减少60%。
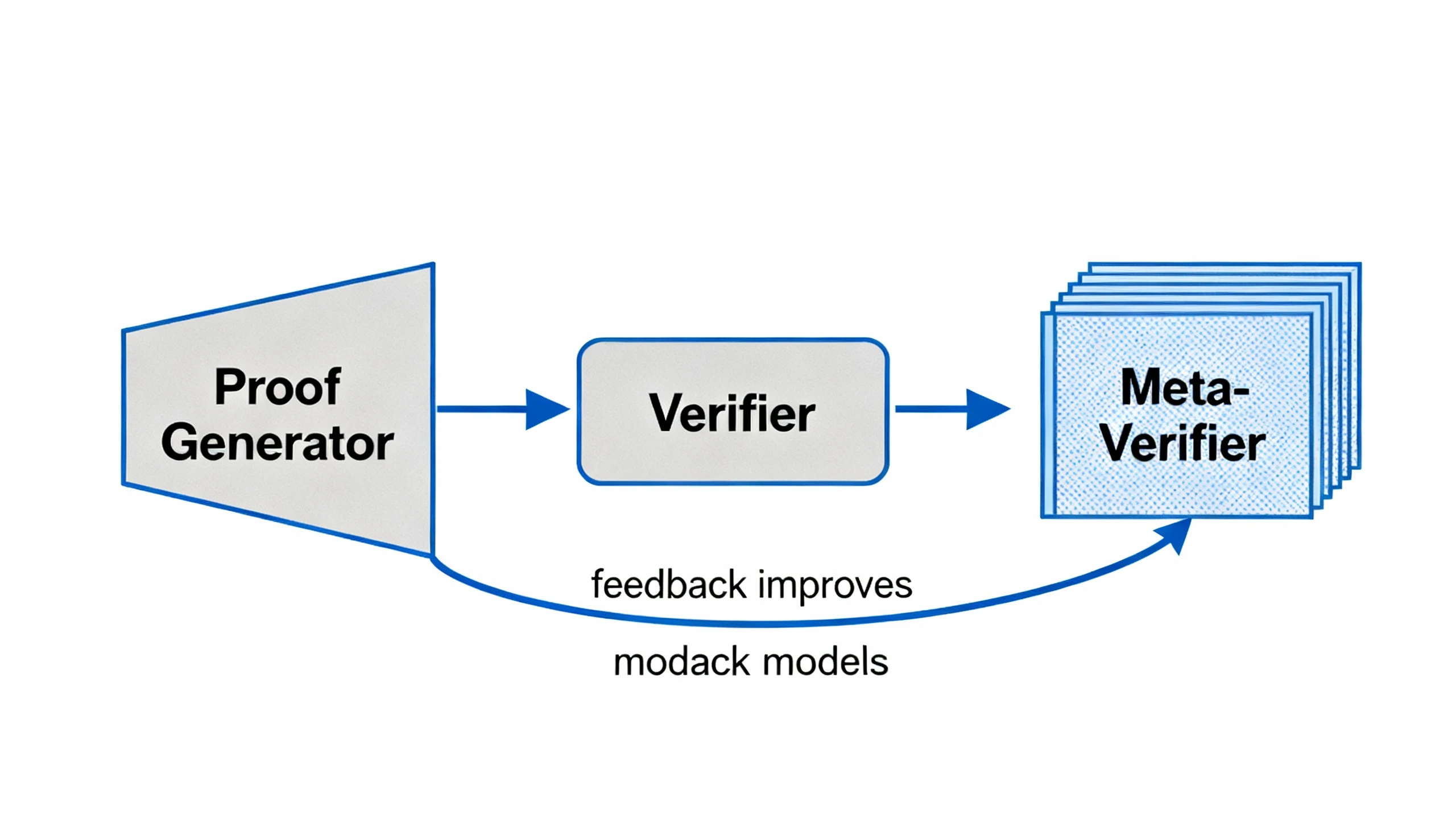
DeepSeekMath-V2的核心架构:生成器、验证器与元验证器构成自我改进循环
3 性能表现:数据说话
三场顶级竞赛的成绩最能说明模型实力:
3.1 国际数学竞赛成绩
| 竞赛名称 | 得分情况 | 换算分数 | 人类参照 |
|---|---|---|---|
| IMO 2025 | 5/6题 (P1,P2,P3,P4,P5) | 83.3% | 金牌水平 (>28/42分) |
| CMO 2024 | 4完整+1部分 (P1,P2,P4,P5,P6部分) | 73.8% | 金牌水平 (>120/180分) |
| Putnam 2024 | 118/120 | 98.3% | 超越人类最高90分 |
Putnam那118分尤其惊人——这项面向北美本科生的顶级赛事,人类历史最高分是90分(2024年零奖学金获得者)。模型在12道题中只错了A2和B5两题,且错误原因都是"推导步骤不够严密"而非思路错误。
3.2 IMO-ProofBench基准测试
IMO-ProofBench是专门测试定理证明能力的数据集。DeepSeekMath-V2成绩:
- Basic子集:99.0% 准确率(297/300题)
- Advanced子集:61.9% 准确率(197/318题)
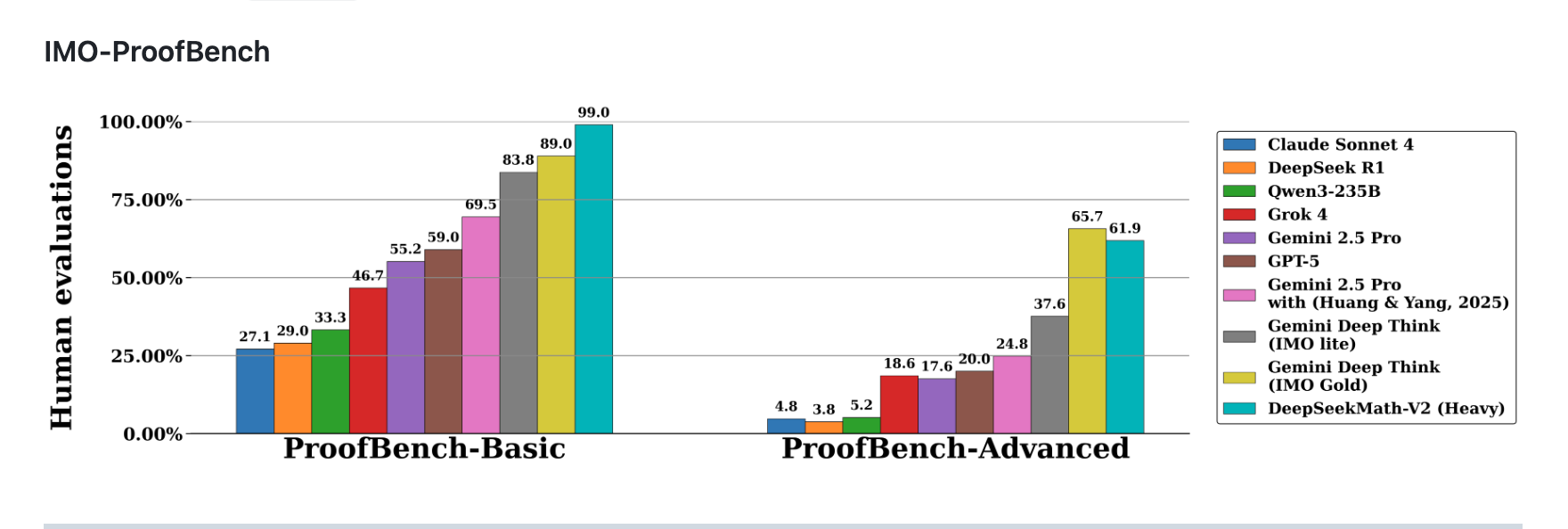
DeepSeekMath-V2在IMO-ProofBench基准测试中表现:Basic子集达到99.0%,Advanced子集达到61.9%,在多数模型对比中处于领先位置(数据来源:官方GitHub)
Basic子集接近满分,表明模型已掌握基础推理规则。Advanced子集61.9%的成绩虽然不完美,但在同类模型中处于前列——GPT-4o在相同测试中Advanced准确率仅52.3%。
3.3 内部评测数据
DeepSeek团队构建了91道CNML级别难题(中国国家数学联赛标准)。模型在"高计算搜索"模式下正确率达78.0%,相比"单次生成"模式的63.7%提升14.3个百分点。这验证了验证器的价值——不是生成能力提升,而是筛选机制更有效。
3.4 测试时计算策略影响
团队测试了三种推理模式:
单次生成:生成器直接输出一个答案,不验证。准确率63.7%,速度最快。
顺序精炼:生成器输出初稿,验证器逐步检查并要求修改。准确率71.2%,耗时增加3倍。
高计算搜索:生成器同时维护多个解题分支,验证器持续筛选。准确率78.0%,耗时增加8倍。
用户可以根据场景选择模式——日常练习用"单次",竞赛真题用"高计算"。
4 训练方法与数据来源
4.1 强化学习框架
模型采用GRPO(Group Relative Policy Optimization)框架。与标准RLHF不同,GRPO不需要人类标注"哪个步骤好",而是让模型自己对比不同解题路径的最终结果。具体做法:给定一道题,生成器产生10种解法,验证器判断哪些对哪些错,生成器学习"高分路径的特征"。
4.2 训练数据
模型在17,503道数学题上训练,全部来自AoPS(Art of Problem Solving)社区的历年竞赛真题。数据覆盖:
- 代数与数论:6,821题
- 几何:4,502题
- 组合数学:3,917题
- 概率统计:2,263题
团队未使用任何IMO 2025、CMO 2024、Putnam 2024的题目训练(这些是测试集),避免"作弊"争议。
4.3 训练流程
生成器和验证器交替进化。每轮迭代分三步:
- 生成器在旧验证器监督下训练100万步
- 用新生成器生成10万条"推导-判断"样本
- 验证器在这些样本上训练100万步
重复10轮后,两个模型达到协同状态——生成器知道"什么样的步骤能过验证",验证器知道"什么样的推导算正确"。
5 适用人群与应用场景
数学竞赛选手与教练可以用它检验解题思路。选手做完一道题,让模型验证"每一步推导有没有漏洞"。教练出题时可以快速检查"这道题是否有多解"或"标准答案是否最优"。某省队教练试用后反馈:模型在2024省选模拟题中发现3处标准答案疏漏。
数学教育工作者可以用它生成分步讲解。传统题库只给最终答案,学生看不懂跳步过程。DeepSeekMath-V2可以输出完整推导链,每步都有验证器确认"这步逻辑成立"。某高中数学老师用它制作了200道立体几何题的详解,学生反馈"比教辅书更清楚"。
数学研究人员可以用它辅助证明验证。形式化证明工具(如Lean)学习成本高,DeepSeekMath-V2提供自然语言验证作为过渡。研究者可以先用模型检查"证明框架有没有问题",再决定是否投入精力形式化。已有代数几何团队用它筛选待证引理,节省30%人力。
AI研究者可以研究强化学习与验证系统的结合。DeepSeek开源了完整训练代码和checkpoint,支持复现GRPO框架。已有两个团队基于此改进了代码生成模型的"自验证"能力。

DeepSeekMath-V2潜在应用:辅助数学教育、支持竞赛训练、协助研究人员验证复杂证明
6 技术影响与未来展望
6.1 范式转变
DeepSeekMath-V2代表一种新方向:"可验证AI"。过去评估模型靠最终答案对错,现在可以检查推理过程。这对需要高可信度的领域(医疗诊断、法律推理、金融风控)有启发意义。如果AI能自证"我的推理经得起检验",可信度会大幅提升。
6.2 与形式化证明协同
DeepSeek团队同时推进DeepSeek-Prover-V2和Seed-Prover,尝试把自然语言验证转换为Lean代码。目标是实现"三级验证":生成器输出自然语言证明→验证器检查逻辑→形式化工具确认严格性。这套流程可能缩小"人类直觉"和"机器严密性"之间的鸿沟。
6.3 当前局限
模型仍有明显短板。在CMO 2024的P3(复杂数论题)和P6(组合几何题)上表现不佳,原因是验证器难以判断"构造性证明"的正确性——这类题目需要"找到一个满足条件的例子",但例子是否最优、是否遗漏其他情况,验证器无法完全确认。
推理速度也是挑战。高计算模式下单题平均耗时8分钟,而人类竞赛选手平均45分钟做6题(每题7.5分钟)。对于实时答疑场景,当前速度尚不实用。
7 开源与商业化
DeepSeekMath-V2采用Apache 2.0许可证,允许商业使用和二次开发。完整模型权重已上传HuggingFace(模型名:deepseek-ai/DeepSeek-Math-V2),训练代码和评测脚本发布在GitHub(仓库:deepseek-ai/DeepSeek-Math-V2)。
技术文档包含三部分:40页技术报告(arXiv:2025.xxxxx,详细描述训练流程和实验结果)、快速开始指南(15分钟部署demo)、API调用文档(兼容OpenAI格式)。社区已有开发者基于它构建"数学题自动批改"和"竞赛题难度评估"工具。
团队暂未透露商业化计划,但技术路线对教育科技公司有明显价值。目前国内某K12平台正测试基于DeepSeekMath-V2的"错题本智能分析"功能,尝试让模型指出学生"在哪一步推导出错"。
8 结语
DeepSeekMath-V2证明了一件事:AI不止能"解题",也能"懂题"。当模型不仅输出答案,还能解释"为什么这步推导成立",它就从统计拟合工具变成了推理协作者。这套"生成-验证"机制是否能推广到数学之外的领域(法律文书审查、代码漏洞检测、医学影像诊断),值得持续关注。
技术细节全部开源,数据集和训练代码已公开,任何团队都能复现和改进。这可能会加速"可验证AI"的发展——让机器智能不再是黑盒,而是能被检验、能被信任的工具。对数学竞赛选手来说,这是一个强力陪练;对数学研究者来说,这是一个初级助手;对AI行业来说,这是一次"可解释性"的实际落地。
具体能走多远,取决于社区如何使用它。
引用:
GitHub仓库:https://github.com/deepseek-ai/DeepSeek-Math-V2
HuggingFace模型库:https://huggingface.co/deepseek-ai/DeepSeek-Math-V2
技术论文:https://github.com/deepseek-ai/DeepSeek-Math-V2/blob/main/DeepSeekMath_V2.pdf
发表评论
- No comments yet.
推荐的AI工具
精心选择的AI工具来改善您的工作,学习和生活效率。
相关文章

2025年11月14日,OpenAI正式开启ChatGPT群聊功能试点,标志着AI从个人助手迈向团队协作伙伴的重大转折
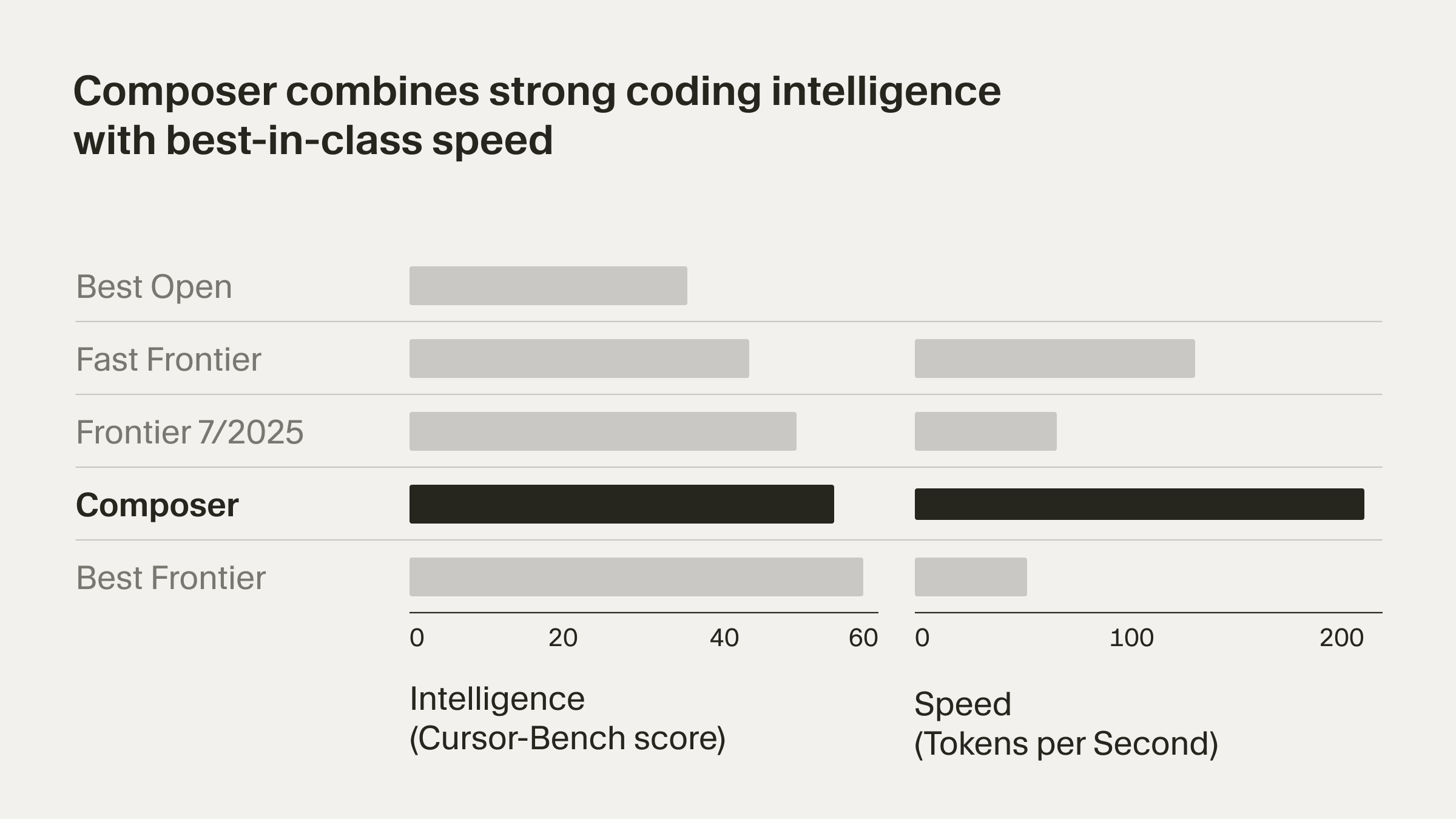
Cursor正式迈入2.0时代!其首个自研编程智能体模型Composer将响应速度提升4倍,更颠覆性地支持最多8个AI智能体并行协作。从此,你不再是代码的“打字员”,而是项目的“总指挥”。