Gemini 3 DeepThink 深度体验:AI推理能力的又一次突破

这是一场意料之外,却又在情理之中的突袭。
坦白说,过去的一年里,我们见惯了各家大模型在跑分榜上的"你追我赶",往往只是零点几个百分点的拉锯战。但这次 DeepThink 的发布,给我的感觉完全不同。它不是在现有基础上做简单的加法,而是在尝试重构模型"思考"的方式。
并不只是"慢思考"
如果说之前的 Chain-of-Thought(思维链)是让模型学会"一步一步地想",那么 Gemini 3 DeepThink 带来的则是并行推理(Parallel Reasoning)。
这是一个非常关键的区别。我们在使用之前的推理模型(比如早期的 o1 系列)时,往往能感觉到它们在进行线性的深度挖掘。模型像是一个钻牛角尖的学生,沿着一条逻辑路径死磕到底。这种方式在解决某些问题时很有效,但一旦初始方向错了,就会在错误的道路上越走越远,最终导致幻觉或逻辑崩塌。
Google 这次展示的"并行推理"技术,让模型拥有了"分身术"。在面对一个复杂的数学难题或逻辑陷阱时,DeepThink 不再孤注一掷,而是同时构建多个假设路径。你可以把它想象成一个围棋高手,脑海中同时推演着未来五步的十几种可能性。它会评估每一条路径的可行性,迅速抛弃那些看起来没前途的死胡同,然后集中算力在最有希望的路径上继续深挖。
这种机制带来的直接体感是:它的"纠错率"极高。在我的初步测试中,对于那些故意设置了前提陷阱的逻辑题,DeepThink 很少会直接跳进坑里,因为它在并行思考的过程中,大概率有一条路径已经发现了前提的谬误。
数据背后的真相:当 GPT-5 遇到劲敌
光谈技术原理未免有些空洞,我们来看看实打实的评测数据。Google 这次放出的基准测试成绩非常硬核,特别是对比了 Claude Sonnet 4.5、GPT-5 Pro 甚至 GPT-5.1 这些顶流选手。
下图展示了三个极具代表性的基准测试对比,数据量非常丰富,建议大家仔细看一看:
详细评测数据对比
Google 官方发布的评测数据覆盖了三个关键维度:推理与知识、科学知识和视觉推理能力。下面是完整的数据对比:
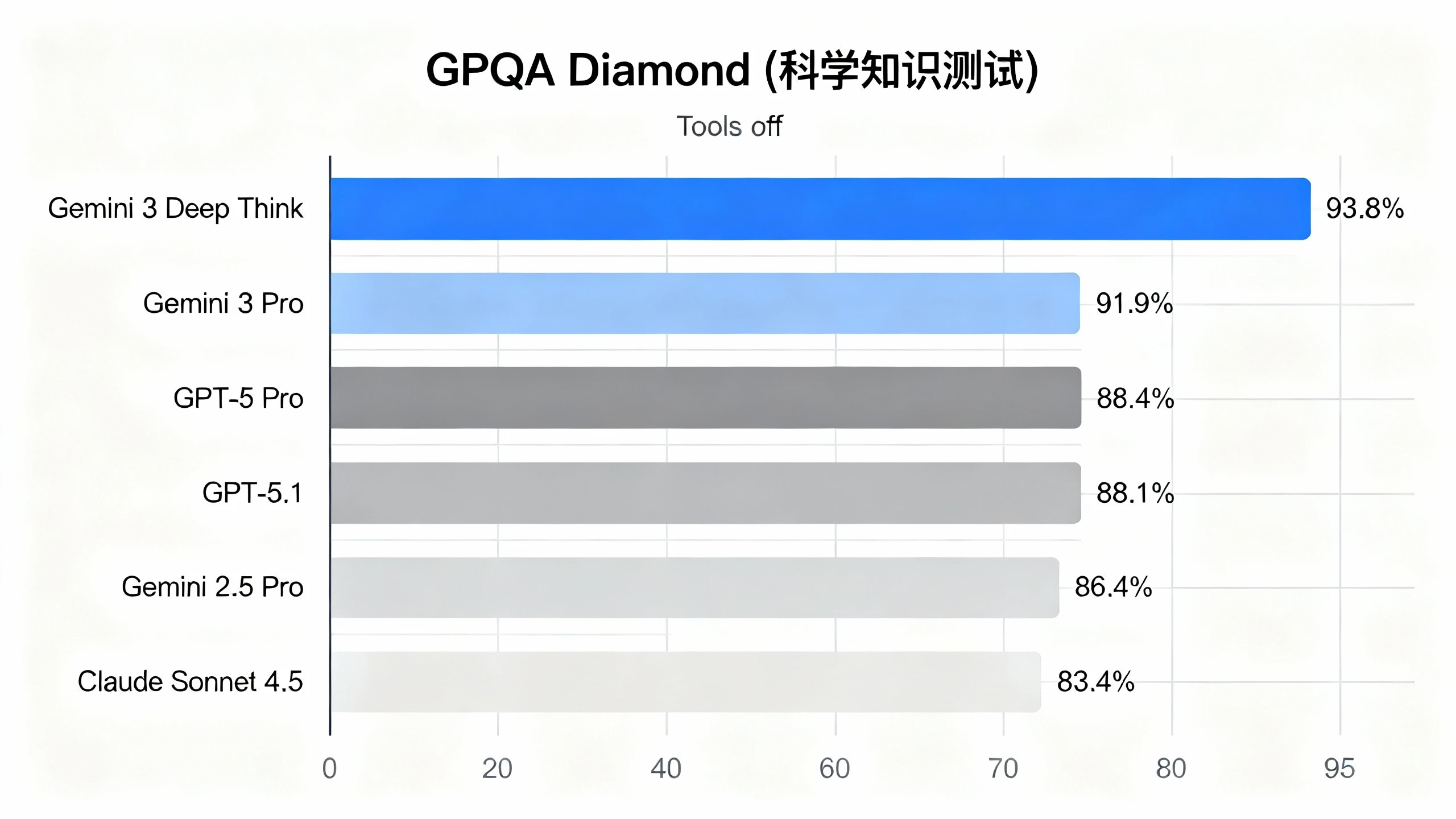
1. Humanity's Last Exam(推理与知识测试)
测试条件:Tools off(不使用外部工具)
这项测试被称为"人类的最后考试",旨在评估模型在开放式问题中的自主推理能力。DeepThink 以 41% 的成绩领跑,比第二名 Gemini 3 Pro 高出 3.5 个百分点,比 GPT-5 Pro 高出整整 10.3 个百分点。
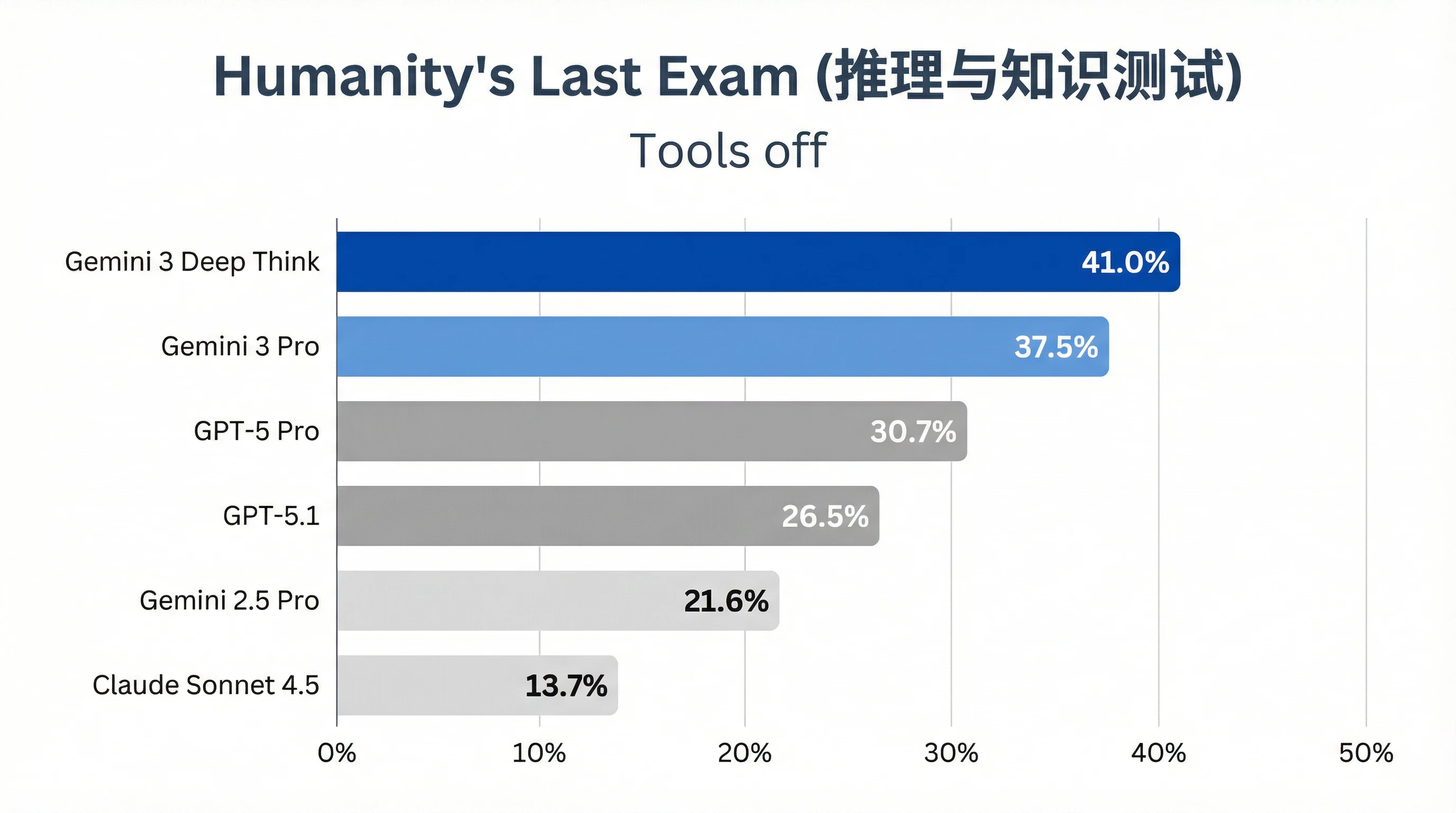
2. GPQA Diamond(科学知识测试)
测试条件:Tools off(不使用外部工具)
GPQA Diamond 是研究生级别的科学问题测试,涵盖物理、化学、生物等多个学科。DeepThink 以 93.8% 的准确率位居榜首,在这个高分区间,每提升 1% 都意味着显著减少了专业级幻觉。
3. ARC-AGI-2(视觉推理谜题)
测试条件:Tools on(允许使用代码执行)
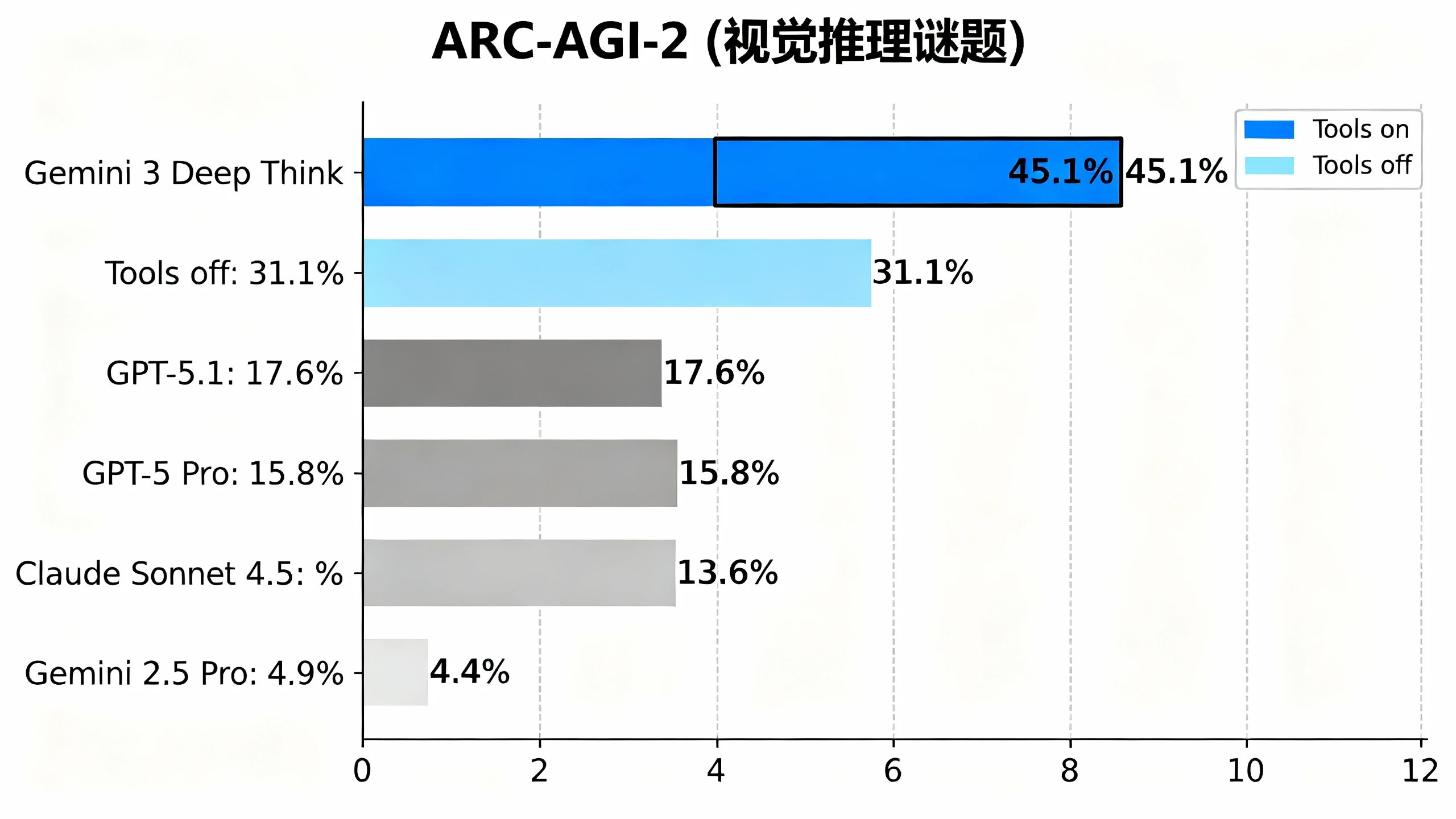
ARC-AGI-2 被认为是最接近测试"通用流体智力"的基准测试,要求模型理解从未见过的抽象视觉模式。DeepThink 的 45.1% 成绩是一个里程碑式的突破,几乎是 GPT-5.1(17.6%)的 2.5 倍,比自家前代 Gemini 2.5 Pro(4.9%)提升了惊人的 820%。
下图是官方发布的综合对比图,三项测试一目了然:
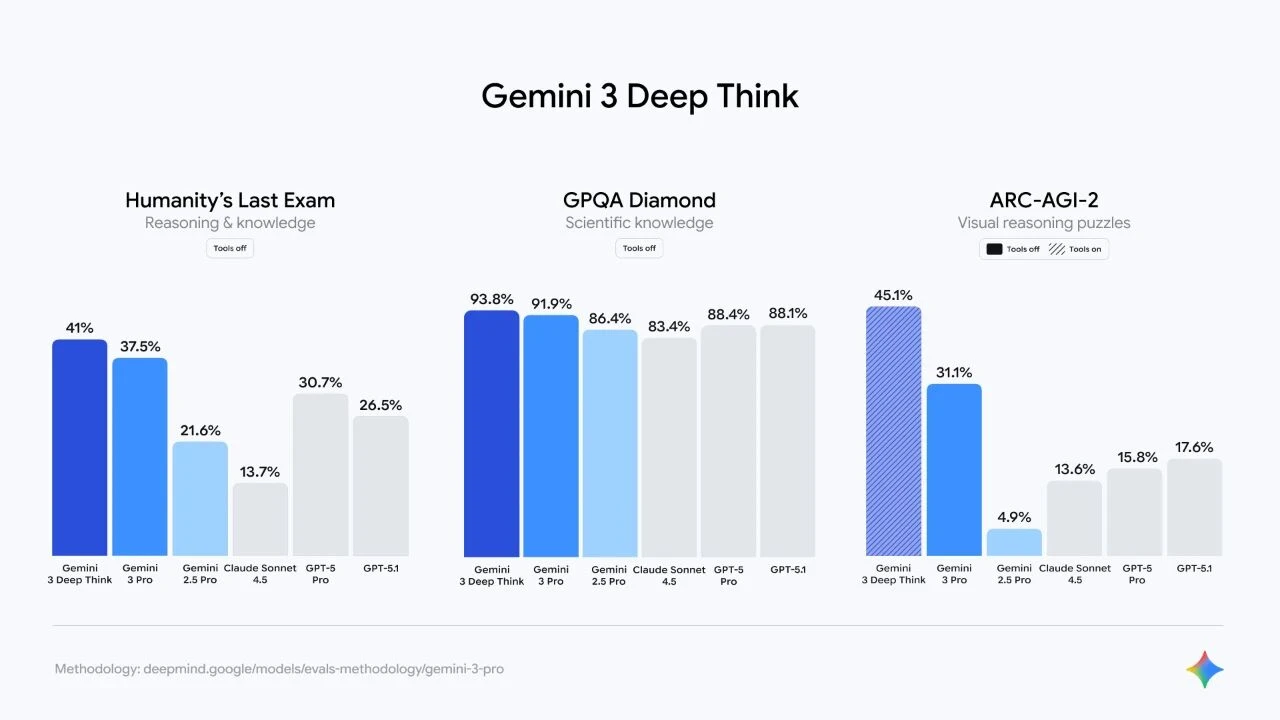
让我们把目光聚焦在最具破坏力的几个数据点上。
首先是 ARC-AGI-2。这不仅仅是一个分数,这是一个分水岭。
熟悉 AI 评测的朋友都知道,ARC(Abstraction and Reasoning Corpus)一直是 LLM 的噩梦。它不考死记硬背的知识,考的是纯粹的视觉逻辑和即时学习能力——也就是大家常说的"通用流体智力"。在很长一段时间里,哪怕是最强的模型,在这个榜单上也只能拿到个位数或刚刚出头的分数。
看图中的数据,Gemini 2.5 Pro 只有 4.9%,这基本上就是"完全看不懂"的状态。Claude Sonnet 4.5 和 GPT-5 Pro 提升到了 13-15% 的区间,虽然有进步,但依然属于"蒙对了一些"。
然而,Gemini 3 DeepThink 直接把这个数字拉升到了 45.1%(Tools on,即允许编写代码辅助)。即便是不使用工具(Tools off),它也达到了 31.1%。这几乎是两倍于 GPT-5.1 的表现。这意味着模型不再只是在做文本预测,它真正理解了抽象的规律,并能将这种理解转化为代码来验证自己的猜想。这种能力的跃升,主要就归功于"并行推理"——在面对从未见过的谜题时,尝试多种可能的变换规则,直到找到正解。
再来看看 Humanity's Last Exam。这个名字听起来很中二,但它是目前公认最难的综合推理测试之一,旨在测试模型在没有具体指令下的自主探索能力。
DeepThink 在这里拿到了 41.0%。作为对比,Claude Sonnet 4.5 只有 13.7%,哪怕是目前市面上极强的 GPT-5 Pro 也只跑到了 30.7%。这 10 个百分点的差距在高端局里是非常恐怖的。它说明当问题变得极端复杂、需要跨学科知识和多步跳跃逻辑时,DeepThink 的"多路思考"模式展现出了碾压级的稳定性。
至于 GPQA Diamond(科学知识),虽然大家的差距没有拉得那么大(DeepThink 93.8% vs GPT-5 Pro 88.4%),但这属于"百尺竿头更进一步"。在 90 分以上的区间,每提升 1 分都意味着减少了大量的专业级幻觉。对于需要用 AI 辅助科研的用户来说,这 5% 的准确率提升可能就是"实验成功"与"查错三天"的区别。
从奥数金牌到日常生产力
如果仅仅是刷榜,DeepThink 还不足以让我如此兴奋。真正让我觉得它"未来可期"的,是它背后的技术渊源。
官方博客透露,Gemini 3 DeepThink 的技术底座,其实是基于那个曾在国际数学奥林匹克竞赛(IMO)和国际大学生程序设计竞赛(ICPC)中达到金牌标准的 Gemini 2.5 变体演进而来。
这意味着什么?意味着这套系统最初就是为了"解决难题"而设计的,而不是为了"陪聊"。
在实际应用场景中,这种能力会如何转化?
如果你是一个程序员,当你把一段充满隐晦 Bug 的代码丢给 DeepThink 时,它不会像普通模型那样直接给你一个似是而非的修复建议。它可能会在后台(也就是它的思维过程中)并行构建三种不同的调试思路:
- 怀疑是内存泄漏;
- 怀疑是并发竞争条件;
- 怀疑是第三方库的版本兼容性。
它会尝试验证这三种假设,最后告诉你:"虽然看起来像内存问题,但经过验证,这实际上是一个罕见的并发死锁,建议这样修改..." 这就是并行推理在工程侧的降维打击。
对于科研工作者,在进行文献综述或假设生成时,DeepThink 可以同时从不同的理论框架出发去解读同一组实验数据,提供更多维度的视角,而不是只吐出最常见的那个解释。
思考的代价与未来
当然,目前 DeepThink 并非没有门槛。作为 Ultra 订阅用户才能使用的功能,它的推理成本显然不低。在实际体验中,开启"Deep Think"模式后,响应速度确实比普通模式要慢一拍。屏幕上闪烁的思考状态图标,时刻提醒着你后台正在燃烧大量的算力。
但这种等待是值得的。我们正在经历 AI 从"System 1"(快思考,直觉反应)向"System 2"(慢思考,逻辑推理)全面进化的时刻。
Gemini 3 DeepThink 的出现,某种程度上打破了 GPT 系列在高端推理领域的垄断感。45.1% 的 ARC 成绩是一个信号,它告诉我们,通往 AGI 的路上,除了堆算力和数据,算法架构上的创新——比如这种模仿人类"深思熟虑"的并行推理机制——依然有着巨大的挖掘空间。
对于普通的 AI 使用者来说,现在的选择变得更加有趣了:如果你只是需要写封邮件、润色文章,普通的 Pro 模型绰绰有余;但如果你真的遇到了一块难啃的骨头,需要一个能陪你一起烧脑、甚至比你思考得更周全的助手,Gemini 3 DeepThink 无疑是目前最值得尝试的工具之一。
引用
https://blog.google/products/gemini/gemini-3-deep-think/
https://x.com/GeminiApp/status/1996656314983109003
发表评论
- No comments yet.
推荐的AI工具
精心选择的AI工具来改善您的工作,学习和生活效率。
相关文章

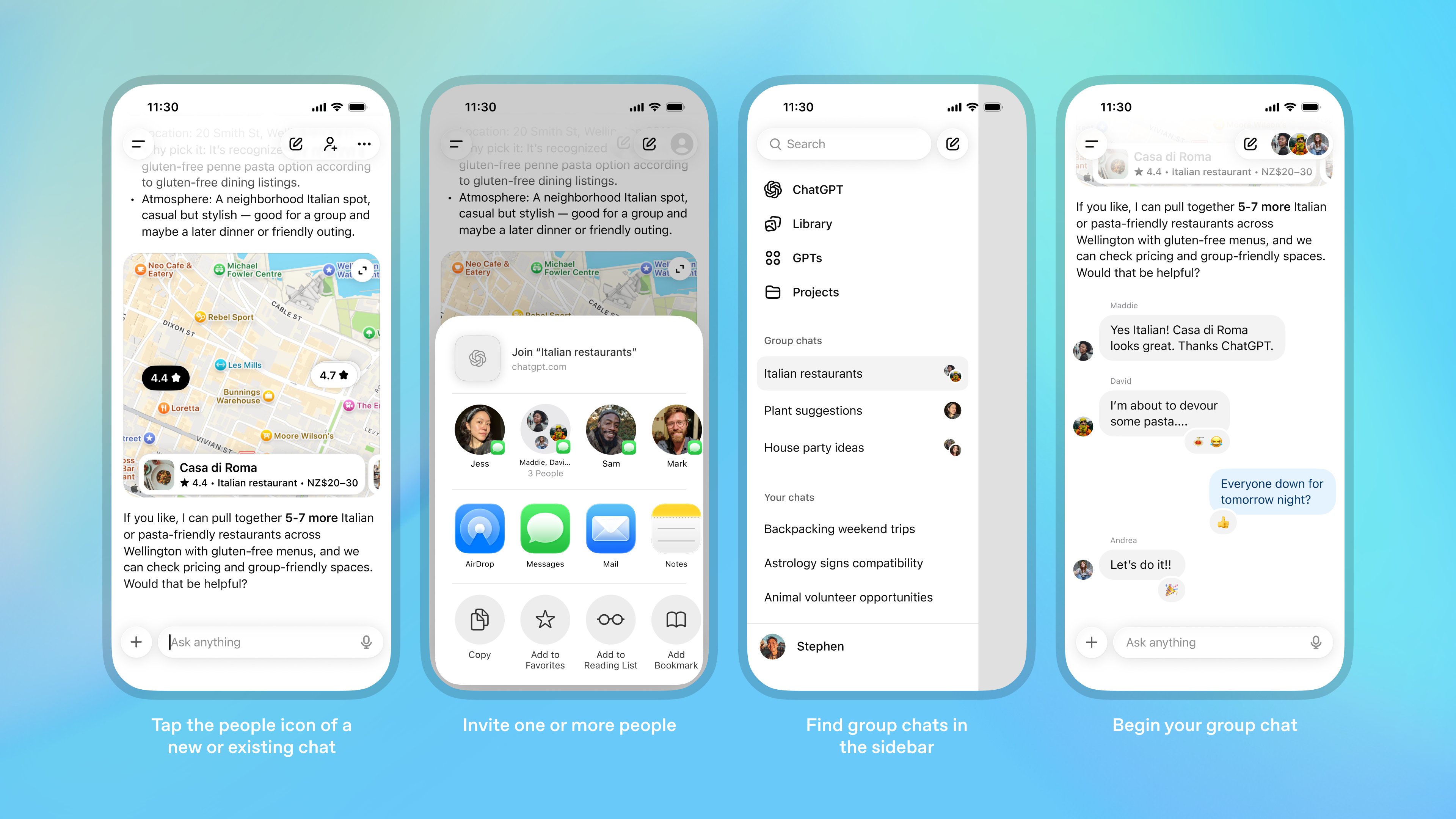
2025年11月14日,OpenAI正式开启ChatGPT群聊功能试点,标志着AI从个人助手迈向团队协作伙伴的重大转折
Cursor正式迈入2.0时代!其首个自研编程智能体模型Composer将响应速度提升4倍,更颠覆性地支持最多8个AI智能体并行协作。从此,你不再是代码的“打字员”,而是项目的“总指挥”。