Gemini 3 Flash 深度解析:推理成本的终结者,Google 这次没留余地

作为一名长期关注AI工具生态的运营者,见惯了各家厂商"刷榜"式的参数竞赛。但Gemini 3 Flash的出现,解决了一个长期困扰行业的痛点:如何在不牺牲推理能力的前提下,将成本和延迟压低到生产环境可接受的水平。
接下来我就从技术参数、成本效益、推理机制以及实际应用四个维度,来深度剖析一下Gemini 3 Flash。
一、定位重构:速度与智力的"不可能三角"
在过去,选择"Flash"类模型通常意味着妥协:你获得了极快的速度和低廉的价格,但不得不忍受较弱的逻辑推理能力,Gemini 3 Flash 正在打破这种刻板印象。
根据官方报告,Gemini 3 Flash 的定位非常精准——它是一款融合了上一代 Pro 级推理能力与 Flash 级响应速度的平衡型产品。
- 速度维度:相比 Gemini 1.5 Flash,它的延迟进一步降低;而对比性能相当的 Gemini 2.5 Pro,其响应速度快了整整 3 倍。
- 成本维度:这是最令人惊讶的部分。它的推理成本仅为 Gemini 2.5 Pro 的 1/10。
- 能力维度:在基准测试中,它并没有因为追求速度而"降智",其核心推理能力与 Pro 级模型保持了惊人的一致性。
对于构建 Agent 工作流或即时交互应用的开发者来说,这意味着你不再需要在"聪明但慢"和"快但笨"之间做艰难的选择。
二、核心技术突破:可调制的"思考"能力
Gemini 3 Flash 最值得关注的技术特性,在于引入了类似 OpenAI o1 系列的"思考(Thinking)"过程,但 Google 走得更远——他们给了开发者控制权。
1. 动态 Thinking Tokens
与传统的"黑盒"推理不同,Gemini 3 Flash 允许模型在输出最终答案前生成"thinking tokens"。这些 token 代表了模型的思考链(Chain of Thought),用于处理复杂的逻辑问题。
- 自适应复杂度:模型可以根据任务的难易程度,动态调整思考的深度。简单的问答直接输出,复杂的代码重构或数学证明则会消耗更多的 thinking tokens。
- 用户可控:开发者可以通过 API 设置 thinking tokens 的预算上限。这给了我们极大的灵活性——在处理非关键任务时限制思考长度以节省成本,在处理核心逻辑时放开限制以确保准确率。
2. 多模态的原生整合
Google 继续发挥其在多模态领域的传统优势。Gemini 3 Flash 不仅仅是文本模型,它在视觉理解、视频分析方面表现出了极高的效率。特别是在长视频上下文中提取关键信息的能力,配合其极低的 token 价格,让视频内容的自动化处理变得在经济上真正可行。
三、性能对标:数据背后的真相
为了客观评估 Gemini 3 Flash 的实力,我们整合了 GPQA、MMMU 以及 SWE-bench 等关键基准测试的数据。
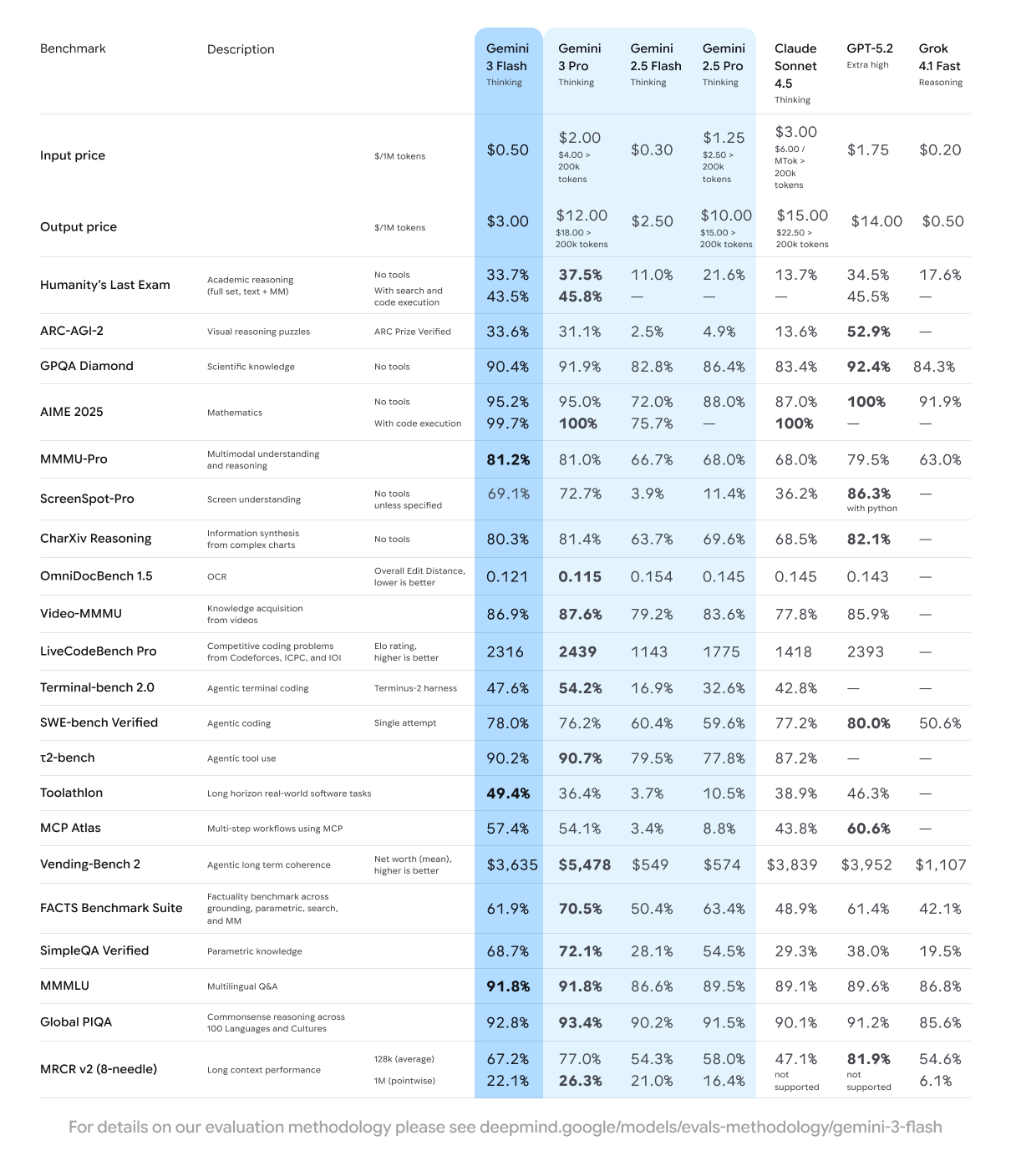
表格关键看点:从官方基准数据中可以看出,Gemini 3 Flash 在 GPQA Diamond(博士级科学问答)测试中取得了 90.4% 的高分,这个成绩不仅远超上一代 Flash 模型,甚至逼近了许多厂商的高端型号。在 MMMU Pro(多模态理解)上 81.2% 的得分证明了其全能性,而 SWE-bench(软件工程)78% 的表现则意味着它完全有能力胜任代码审查和生成任务。最重要的是,它在仅需 1/10 成本的前提下,实现了这些成绩。
核心发现:
- 性价比的帕累托前沿:在"成本-性能"的坐标系中,Gemini 3 Flash 处于目前市场的最优区间。它用极低的资源消耗,实现了接近行业最佳的效能。
- 开发者关切指标:对于编程和逻辑推理任务,Gemini 3 Flash 的表现明显优于同价位的 Claude 3 Haiku 或 GPT-4o mini,甚至在部分场景下可以替代昂贵的 GPT-4o 或 Claude 3.5 Sonnet。
四、成本效益分析:开发者的精算账
定价策略往往决定了技术落地的广度。Google 这次给出的价格极具攻击性:
- 输入(Input):$0.50 / 1M tokens
- 输出(Output):$3.00 / 1M tokens(如果不使用 Thinking 功能,输出成本通常更低)
这意味着什么?
假设你正在开发一个需要大量读取文档的 RAG(检索增强生成)应用。使用 Gemini 3 Flash,你读取 200 万字(约 2M tokens)的上下文资料,仅需花费 1 美元。
对于 Agent 开发者而言,Agent 往往需要进行多轮自我反思和工具调用。以往这种模式因为 token 消耗巨大而难以商业化,现在 Gemini 3 Flash 将这一门槛降低了一个数量级。
五、适用场景建议
基于上述分析,我建议以下几类用户重点关注 Gemini 3 Flash:
- 高频迭代的开发者:在代码编写、单元测试生成、日志分析等场景中,Gemini 3 Flash 的 78% SWE-bench 分数配合低延迟,能提供极其流畅的 IDE 体验。
- Agent 系统构建者:复杂的 Agent 工作流需要大量的中间推理步骤。利用可控的 thinking tokens,你可以在保持 Agent 聪明的同时候,严格控制每一轮交互的成本。
- 企业级数据处理:通过 Vertex AI 接入,企业可以利用其处理海量非结构化数据(合同、财报、视频会议录像),而不必担心预算超支。
- 实时交互应用:客服机器人、语音助手等对延迟敏感的场景,Gemini 3 Flash 是目前的最佳选择。
六、获取方式与生态
Google 已经通过全渠道开放了 Gemini 3 Flash 的访问:
- 开发者:通过 Google AI Studio 和 Gemini API 即可直接调用。
- 企业用户:Vertex AI 已经同步上线,支持企业级的安全合规部署。
- 普通用户:Gemini App(网页版和移动端)已经将默认模型切换为 Gemini 3 Flash,用户可以免费体验其带来的速度提升。
- 前沿探索:通过 Google Antigravity 计划,部分开发者可以提前试用更激进的功能特性。
七、总结:务实派的胜利
Gemini 3 Flash 不是那种只会写诗或画图的"玩具"模型,它是 Google 为工程界递上的一把瑞士军刀。
虽然对于追求人类认知极限的科研任务,我们可能仍需要 Gemini 3 Pro 甚至未来的 Ultra 版本;但对于 95% 的实际应用场景——从代码补全到文档摘要,从数据清洗到简单的逻辑推理——Gemini 3 Flash 提供了目前市场上最优的解法。
一句话建议:如果你的项目还在使用上一代的 Flash 模型,或者为了成本还在忍受 7B 小模型的智力局限,现在是时候迁移到 Gemini 3 Flash 了。这不仅仅是一次升级,更是对产品成本结构的重构。
引用:https://blog.google/products/gemini/gemini-3-flash/
发表评论
- No comments yet.
推荐的AI工具
精心选择的AI工具来改善您的工作,学习和生活效率。
相关文章

2025年11月14日,OpenAI正式开启ChatGPT群聊功能试点,标志着AI从个人助手迈向团队协作伙伴的重大转折
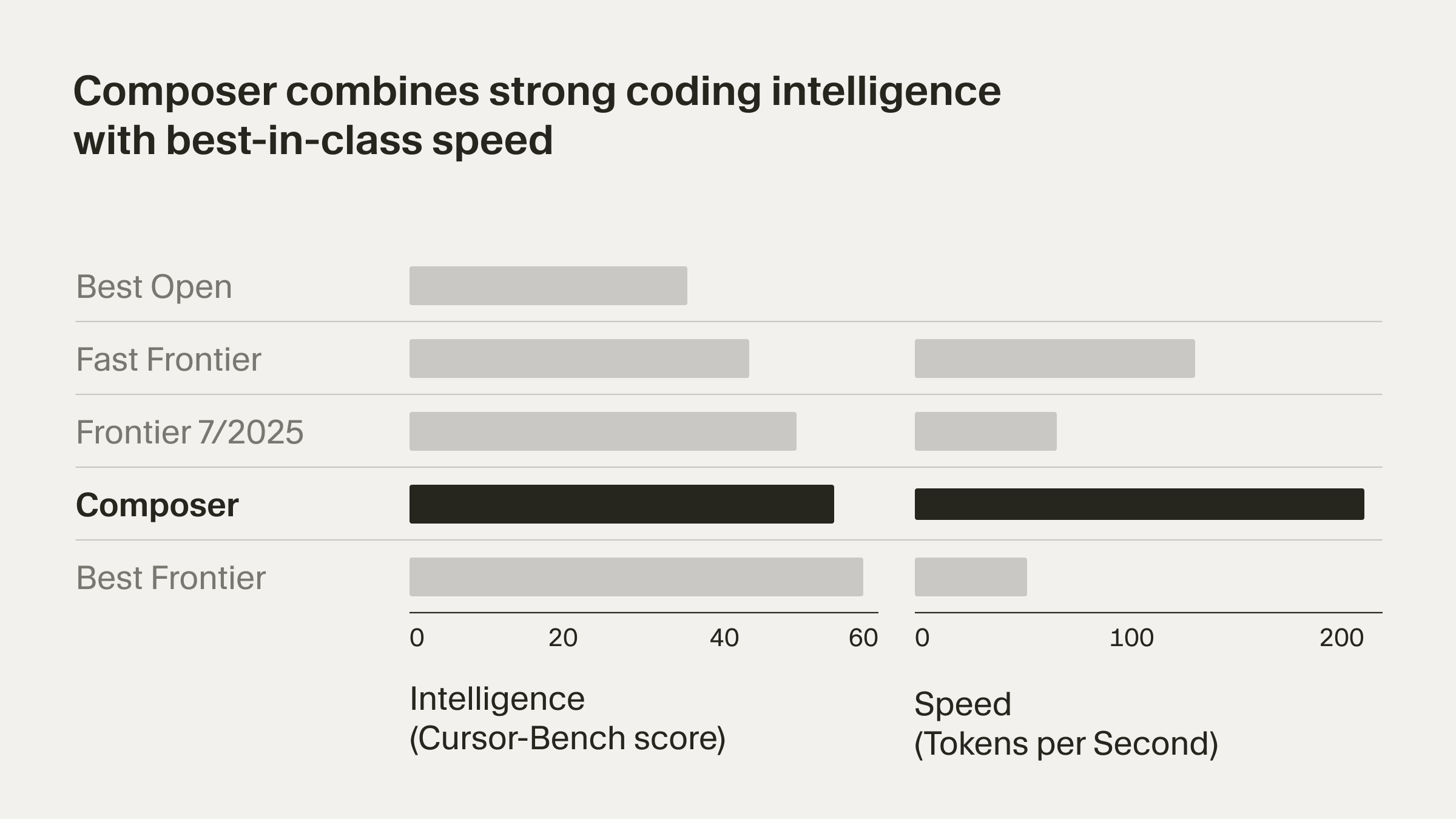
Cursor正式迈入2.0时代!其首个自研编程智能体模型Composer将响应速度提升4倍,更颠覆性地支持最多8个AI智能体并行协作。从此,你不再是代码的“打字员”,而是项目的“总指挥”。