Grok 4.1技术解析-幻觉更低、速度更快


图1:xAI Grok 4.1代表了新一代对话AI技术的进步,在情感理解和事实一致性上实现了重大突破
经常用AI工具的人应该知道,这两个改进打中了大模型应用的痛点。情感理解不足会让对话显得生硬,幻觉问题直接影响信息可信度。Grok 4.1能在这两个维度同时突破,值得仔细看看。
幻觉率大幅降低:从12.09% 到4.22%
幻觉(Hallucination)指的是AI模型生成看似合理但实际上不准确或者虚构的信息。这是大语言模型应用中的核心问题之一。当你问一个事实性问题,模型却给出了编造的数据或错误的解释,这就是典型的幻觉。
Grok 4.1在这个指标上的进步相当显著。官方数据显示,非推理模式下的幻觉率从前代Grok 4的大约12.09%降至了4.2%左右,几乎是三倍的改善。更细致的测试来自FActScore这个专门评估事实准确性的基准测试,在数百个人物传记类问题上,Grok 4.1的错误率从大约10%下降到了不到3%。
这个改善幅度大概说明什么?举个实际场景:当你用AI工具查询行业数据、研究某个人物背景或是了解技术细节时,能更放心地依赖它的回答。虽然仍然需要保持批判性思维,但错误信息减少确实能提高使用效率,成本降了。
xAI表示,他们在后期训练中特别针对信息查找类提示进行了优化。这是一个明智的选择——比起创意性对话,事实性查询对准确性的要求更高,也更容易衡量效果。
情感理解能力跃升:EQ-Bench创纪录

图2:Grok 4.1在关键技术指标上的显著提升:幻觉率降低三倍,事实准确性大幅改善,情商评分创新高
如果说幻觉率关乎准不准,那么情感理解就关乎像不像人。在实际使用中,很多AI工具的回答虽然逻辑上没问题,但总觉得缺点人味,特别是在处理带有情绪色彩的问题时,往往显得模板化和生硬。
Grok 4.1在EQ-Bench情商基准测试中情商分破了1500,比前代提高了100多分,创下了这个测试的新纪录。EQ-Bench主要评估模型在理解、共情和人际交往能力方面的表现。这个分数的提升,Grok 4.1在解读用户意图、捕捉情绪细微差别方面应该做得更好了。
具体体现在哪?官方描述是“更敏锐地感知微妙的意图,更具吸引力,人格也更连贯”。翻译成人话就是:当你用带有情绪的语气提问时,Grok 4.1不会只给你一个公式化的回复,而是能在理解你的情绪状态后,给出更有针对性的回应。
这种能力的提升不只在“聊天”场景下有用。对于需要复杂交互的工作场景——比如写作辅助、内容讨论、思路梳理——一个能够理解你意图并灵活响应的AI,显然比一个只会按模板回答的机器更高效。创意写作评测中,Grok 4.1得分为1722,相比xAI之前最好的成绩提高了近600分,人味回来了。
技术实现:智能体推理模型的应用
这些改进是怎么实现的?xAI透露了一个关键技术细节:他们开发了一种新方法,利用前沿的智能体推理模型(agentic reasoning models)作为奖励模型,让系统能够大规模地自主评估和迭代响应。
这听起来有点抽象,简单来说就是:估计是用了个更强的AI模型来评判另一个AI的输出质量,然后通过强化学习不断优化。这比传统的人工标注方式更高效,也能覆盖更多样的场景。Grok 4.1的改进就是建立在Grok 4的大规模强化学习基础设施之上,重点优化了模型的风格、人格、帮助性和对齐度。
从工程角度看,这种方法的价值在于解决了一个矛盾:你想让模型在很多细微维度上都表现得好(比如既准确又有情商),但人工很难为每个维度都设计出精确的评价标准。让AI来评判AI,某种程度上就是用机器的一致性和规模化能力来弥补人工标注的局限性。
实测表现:榜单第一与用户偏好
Grok 4.1的进步不只是实验室数据,实际表现也印证了这些改进,在LMArena文本榜单上,Grok 4.1的“思考模式”(代号quasarflux)目前位居榜首,Elo得分为1483。甚至它的“非推理模式”(代号tensor)也排在第二位,得分1465,超过了很多竞品的完整推理版本。这相比Grok 4的第33名,是一个相当大的跳跃。
LMArena是一个盲测平台,用户不知道自己在使用哪个模型,只根据实际体验投票。这种榜单的参考价值很高,因为它反映的是真实用户的直观感受,而不是实验室的测试指标。
灰度测试阶段的数据更直接,在11月1日到14日的两周内,xAI在实际流量上进行了盲测对比,记得没错的话,好像是六成多用户选了它。这个比例相当高了——超过60%的胜率,绝大多数用户都能明显感知到体验上的提升。
Grok 4.1提供了两种模式供用户选择:普通Grok4.1适合快速响应;Grok4.1 Thinking则会进行更深入的推理---目前都免费开放给所有用户使用
对用户意味着什么?
介绍完技术指标和测试数据,我们来说说实际应用价值。Grok 4.1的这两大改进——降低幻觉率和提升情感理解——解决的都是实际使用中的具体问题。
内容创作者查资料更靠谱了,写东西时,AI能懂你的情绪了。当你需要一个能理解你创作意图的AI伙伴时,这些能力的提升直接转化为工作效率。
对于产品经理和开发者,更准确的信息查询能力可以减少验证成本。当你用AI工具查询技术文档、研究竞品功能或者了解行业趋势时,更低的错误率意味着你可以更放心地基于其输出做决策。
对于普通用户,更自然的对话体验和更可靠的信息提供,让AI助手从能用变成好用。无论是日常问答、学习辅助还是复杂问题解决,体验的流畅度都会提升。
顺便说一句,Grok 4.1对所有用户免费。在当前大部分顶级AI模型都需要订阅的情况下,这个决定降低了使用门槛。你可以零成本地尝试,看看它是否适合自己的工作流。
结语:AI对话工具的新标杆
Grok 4.1的发布显示了AI对话工具的一个趋势:不再只是堆参数量和基准测试分数,而是真正关注实际使用中的用户体验。幻觉率从大约12.09%降至不到5%,情商测试创纪录,这些数字背后是对准确和像人这两个核心需求的实在回应。
从技术角度看,用智能体推理模型来评估和优化响应质量,代表了一种新的工程范式。从应用角度看,免费开放最顶级模型的做法,降低了普通用户接触先进技术的门槛,很赞,xAI很大气。
对于AI工具的关注者来说,Grok 4.1值得一试。不过和任何工具一样,它是否适合你的具体场景,还需要亲自体验才知道。但至少在情感理解和事实准确性这两个维度上,它确实推高了行业标准。
你是否已经体验过Grok 4.1?欢迎在评论区分享你的使用感受和发现的新特性!
发表评论
- No comments yet.
推荐的AI工具
精心选择的AI工具来改善您的工作,学习和生活效率。
相关文章

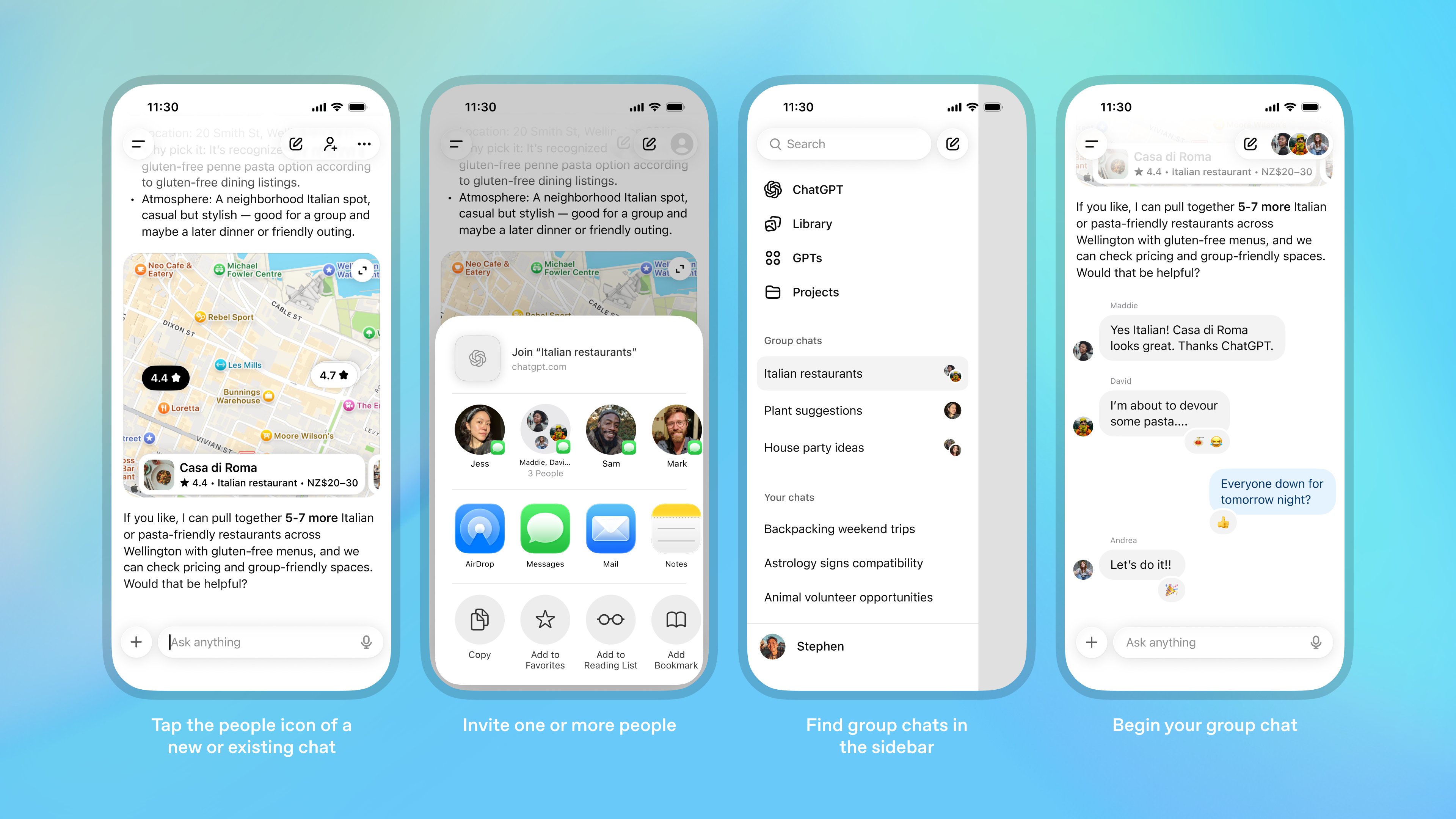
2025年11月14日,OpenAI正式开启ChatGPT群聊功能试点,标志着AI从个人助手迈向团队协作伙伴的重大转折
Cursor正式迈入2.0时代!其首个自研编程智能体模型Composer将响应速度提升4倍,更颠覆性地支持最多8个AI智能体并行协作。从此,你不再是代码的“打字员”,而是项目的“总指挥”。