Kimi Linear横空出世:颠覆Transformer的注意力架构,长文本处理效率飙升6倍
2025年10月31日,月之暗面(Moonshot AI)正式发布全新混合线性注意力架构Kimi Linear,这不仅是一次技术迭代,更可能是下一代AI智能体发展的基石技术。
传统Transformer的瓶颈:为何需要新的注意力架构?
传统的Transformer架构凭借其强大的注意力机制,奠定了过去五年大语言模型发展的基础。然而,随着AI应用场景的扩展,特别是朝向智能体(Agent)和长文本理解方向演进,传统架构的瓶颈日益凸显。
传统Transformer的核心问题在于其二次方时间复杂度——当序列长度增加10倍时,计算量需要增加100倍。同时,在自回归生成过程中,Key-Value缓存(KV Cache)会随着序列长度线性增长,消耗大量显存资源。
这意味着,处理百万token级别的长文本时,传统方法在计算上几乎不可行。这正是月之暗面团队提出Kimi Linear的根本动机。
Kimi Linear的核心创新:三大技术突破
2.1 Kimi Delta Attention(KDA):精细化的门控机制
Kimi Linear的核心是一种称为Kimi Delta Attention(KDA)的新型线性注意力模块。与之前的方法相比,KDA引入了细粒度的对角门控机制。
通俗地讲,传统的线性注意力像是一个“一刀切”的门卫,对所有信息采用相同的遗忘速率。而KDA则为每个信息特征维度配备了独立的“门卫”,可以更精细地决定保留哪些关键信息、遗忘哪些冗余内容。这种设计使得KDA能够更精确地调控其有限的RNN状态记忆,选择性地保留关键信息,遗忘无关噪声。
2.2 3:1混合架构:效率与性能的黄金平衡
Kimi Linear采用了创新的混合架构设计,以3:1的比例将KDA层与全注意力层(MLA)交错排列。即每3个KDA线性注意力层后,插入1个全注意力层。
月之暗面团队通过大量实验发现,这一比例是实现性能和效率最佳平衡的“甜点区”。高于此比例会导致模型性能下降,低于此比例则无法充分体现效率优势。
这种设计使得Kimi Linear在生成长序列时,通过全注意力层保持全局信息流,同时将内存和KV缓存的使用量降低高达75%。
2.3 硬件优化与无位置编码(NoPE)
Kimi Linear中所有全注意力层都不使用任何显式的位置编码(NoPE),这一设计选择背后的考量十分深刻。模型将编码位置信息的责任完全交给了KDA层,而全局注意力层则可以专注于纯粹的内容关联。
在硬件优化方面,KDA采用了一种特制的块处理并行算法,显著提升了计算效率。这使得KDA的算子效率比标准DPLR提升了约100%。
性能实测:全面超越传统方案
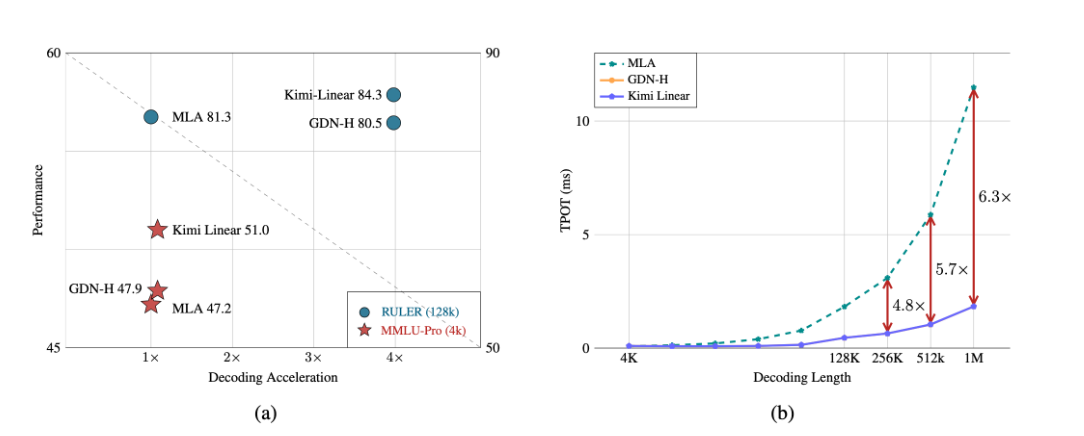
3.1 性能对比数据
下表概括了Kimi Linear与传统架构在关键指标上的对比结果:
| 性能指标 | 传统全注意力模型(MLA) | Kimi Linear | 提升幅度 |
|---|---|---|---|
| 解码吞吐量(1M token) | 11.48ms/token | 1.84ms/token | 提升6.3倍 |
| KV缓存占用 | 基准 | 减少75% | 大幅降低 |
| 长上下文性能(RULER) | 81.3分 | 84.3分 | 显著提升 |
| 通用知识(MMLU-Pro) | 47.2分 | 51.0分 | 全面领先 |
3.2 多场景性能优势
根据技术报告,在相同的训练条件下(1.4万亿token预训练,480亿总参数,30亿激活参数),Kimi Linear在多个权威基准测试中展现出全面优势:
. 短上下文任务:在MMLU、BBH、HellaSwag等通用知识基准上,Kimi Linear得分全面领先。
. 长上下文理解:在128K上下文长度的RULER等基准测试中,取得了最高分,证明了其卓越的长文本信息检索和关联能力。
. 数学与代码能力:在GSM8K、MATH、CRUXEval等数学和代码推理任务上领先。
. 强化学习:在需要多步推理的强化学习任务中,Kimi Linear展现出更快的收敛速度和更高的最终性能。
对AI开发者的实际意义
4.1 降低长文本处理成本
Kimi Linear大幅减少KV缓存意味着可以用更少的硬件资源处理更长的文档,如法律合同、学术论文、代码库等。这对于需要处理超长文本的企业应用来说,可以显著降低计算成本。
4.2 加速AI智能体发展
Kimi Linear架构特别适合需要长序列推理的AI智能体应用。传统的AI智能体在长时间跨度的规划和决策中面临巨大计算挑战,而Kimi Linear的效率优势为复杂决策任务提供了可行的技术基础。
4.3 开源生态与易用性
月之暗面已开源KDA内核的核心代码,并在Hugging Face等平台发布了预训练模型检查点(如 moonshotai/Kimi-Linear-48B-A3B-Instruct),开发者可以立即下载并体验。主流的推理加速框架vLLM也已宣布支持Kimi Linear架构,便于投入实际生产环境。
技术架构深入解析
5.1 Kimi Delta Attention的工作原理
KDA是一种新型的门控线性注意力变体,它在Gated DeltaNet(GDN)的基础上进行了关键改进。其核心创新是引入了细粒度的对角门控,取代了GDN中的标量遗忘门。
从数学角度看,KDA的状态转移可以被视为一种特殊的对角加低秩(DPLR)矩阵。这种结构使得KDA能够通过定制的分块并行算法,在保持表达力的同时实现硬件高效计算。
5.2 混合架构的设计哲学
3:1的混合比例不是随意选择的,而是经过大量实验验证的“黄金比例”。研究发现: . 7:1比例:虽然计算效率更高,但模型性能明显下降
. 1:1比例:性能稳定,但速度优势不明显
. 3:1比例:在效率和性能之间实现了最佳平衡
这种设计体现了“专业分工”的思想:KDA层负责高效的局部信息处理,而全注意力层周期性地进行全局信息整合。
未来展望与行业影响
Kimi Linear的推出标志着大模型的发展重点从单纯“堆参数”转向了“优化底层结构”的新阶段。正如一位研究人员所言:“这只是一个中间阶段,最终我们仍然在朝着实现无限上下文模型迈进。”
对于整个行业来说,Kimi Linear证明了线性注意力架构不仅可以提高效率,还能提升模型性能,这可能会影响未来大模型的架构设计方向。更多公司和研究团队可能会转向线性注意力的研究,推动整个领域向更高效的方向发展。
结语
Kimi Linear的出现不仅仅是一项技术突破,更为整个行业指明了发展方向。效率与性能可以兼得,关键在于基础架构的创新。
对于AI开发者来说,建议尽快熟悉这一架构,因为它很可能成为下一代AI应用的基石技术。随着vLLM等主流推理框架已宣布支持Kimi Linear架构,这项技术将很快在各类AI应用中得到广泛采用。
AI的发展不再只是“更大”,而是“更智能”——而Kimi Linear正是这一转变的关键催化剂。
项目地址
HuggingFace模型库:https://huggingface.co/moonshotai/Kimi-Linear-48B-A3B-Instruct 技术论文:https://github.com/MoonshotAI/Kimi-Linear/blob/master/tech_report.pdf
Kimi Linear代表了AI基础设施的创新浪潮,而整个AI工具生态正以前所未有的速度演进。为了帮助您持续追踪像Kimi Linear这样的前沿工具与洞察行业趋势,欢迎收藏我们站点 https://aiwith.me/
发表评论
- No comments yet.
推荐的AI工具
精心选择的AI工具来改善您的工作,学习和生活效率。
相关文章

2025年11月14日,OpenAI正式开启ChatGPT群聊功能试点,标志着AI从个人助手迈向团队协作伙伴的重大转折
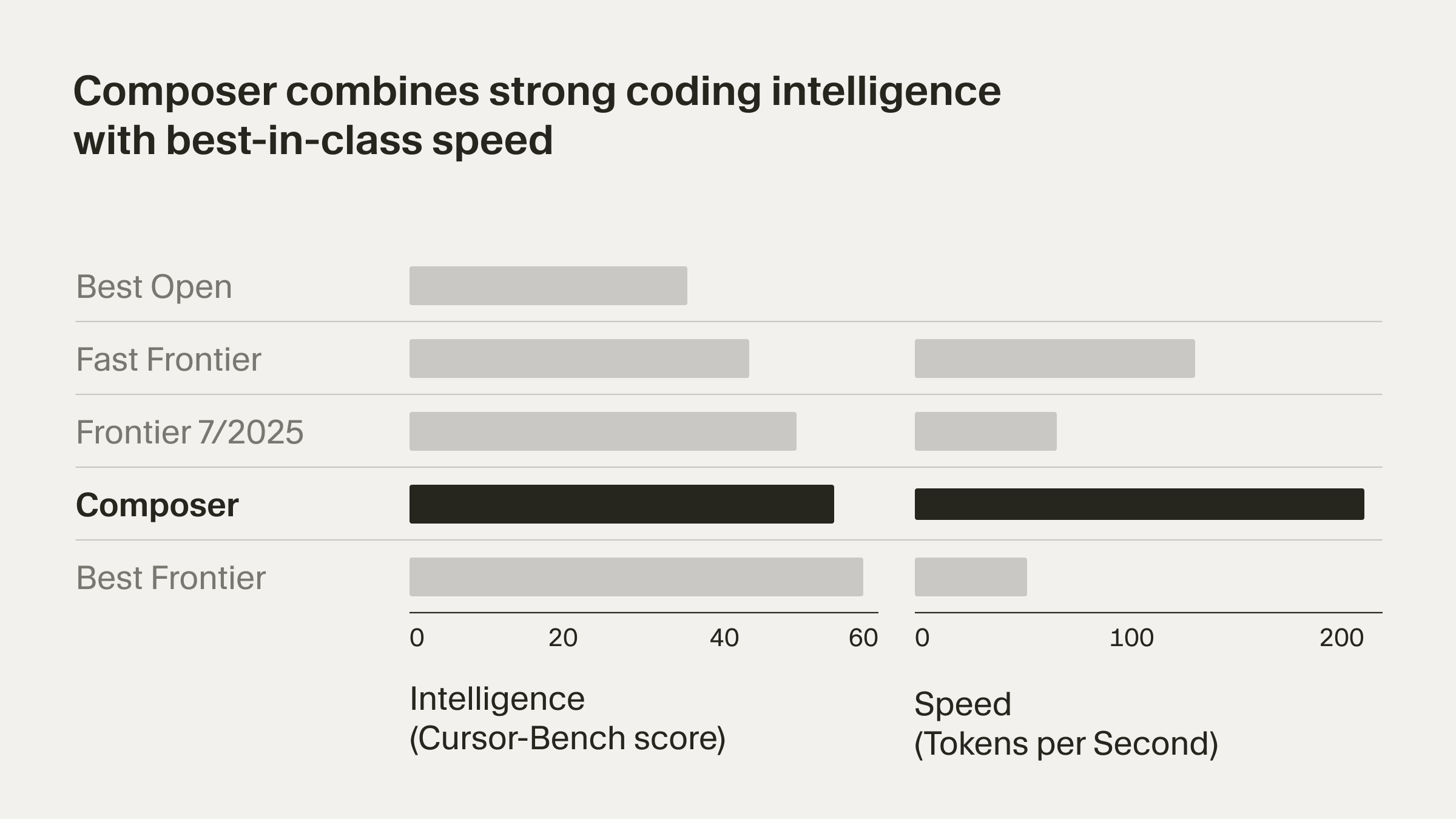
Cursor正式迈入2.0时代!其首个自研编程智能体模型Composer将响应速度提升4倍,更颠覆性地支持最多8个AI智能体并行协作。从此,你不再是代码的“打字员”,而是项目的“总指挥”。