OpenAI双杀器来袭:GPT-5.1 Pro和GPT-5.1-Codex-Max首创压缩机制,24小时连续编程成现实
11月20日,OpenAI没有选择召开发布会,也没有准备华丽的宣传片,仅用两句话的公告就丢出了两个重磅炸弹:GPT-5.1 Pro和GPT-5.1-Codex-Max。
前者将GPT-5.1的智商和情商推向新高度,后者直接瞄准了开发者最头疼的问题——长时间、大规模的代码工程。这次发布最大的看点在于GPT-5.1-Codex-Max首次引入了压缩机制,让AI能够在数百万token的上下文中连续工作超过24小时,处理项目重构、深度调试这类过去难以想象的任务。
77.9%的SWE-bench Verified得分、30%的token效率提升、原生Windows支持。这些数字意味着什么?和Claude Sonnet 4.5、Gemini 3 Pro这些竞品相比,OpenAI这次的底牌到底有多硬?让我们用数据说话。

图1:OpenAI同日发布GPT-5.1 Pro和GPT-5.1-Codex-Max,开启AI编码新纪元
双剑出鞘:GPT-5.1 Pro与Codex-Max各有所长
OpenAI这次同时推出两个模型,定位清晰而互补。
GPT-5.1 Pro:全能型智能升级
GPT-5.1 Pro是在GPT-5.1基础上的“增强版”,主打更强的推理能力和更高的情商表现。虽然官方公告只有两句话,但在多个基准测试中,GPT-5.1 Pro的表现已经证明了其实力。在AIME 2025数学竞赛中,它在启用代码执行的情况下达到100%满分,纯推理模式下也有约71%的成绩。在编码方面,HumanEval基准测试中得分高达94.1%,展现出近乎人类水平的代码生成能力。
这个模型已向所有Pro订阅用户开放,主要服务于需要高级推理、复杂问题解决和多模态理解的场景。虽然在某些基准测试上落后于Gemini 3 Pro,但其在开发者体验、响应速度和生态成熟度上仍然占据优势。
GPT-5.1-Codex-Max:为开发者而生的编码利器
真正的明星是GPT-5.1-Codex-Max。这个模型是OpenAI在GPT-5.1架构上专门为软件工程、数学和研究任务训练的智能体。相比于通用模型,它的特点可以用三个关键词概括:
- 原生压缩机制:这是OpenAI首次在模型层面内置的“上下文管理”能力,能够处理数百万token,支持长达24小时以上的连续工作。
- Extra High推理模式:新增的xhigh模式允许模型想得更久,用更长的推理时间换取更高的准确率。
- 原生Windows支持:OpenAI史上首次支持Windows环境运行。这为大量.NET和Windows开发者打开了大门。
这个模型已经集成在Codex CLI、IDE插件(如VS Code)、云端界面以及代码审查工具中。11月20日起,ChatGPT Plus、Pro、Business、Edu和Enterprise用户可以通过Codex平台使用,API接口也即将发布。
技术突破:压缩机制到底是什么?
“压缩机制”听起来像个营销概念,但实际上它解决了AI编码领域的一个核心痛点。
问题:上下文窗口的诅咒
传统AI模型在处理长任务时面临一个死结:上下文窗口有限。当你要求AI重构一个大型项目或进行深度调试时,它需要不断阅读代码、运行测试、修复错误、再次过一遍测试——这个循环可能需要数小时甚至数十小时。但随着对话轮次的增加,上下文会越来越臃,模型很快就会“忘记”之前做了什么,或者达到token限制直接崩溃。
方案:自动上下文管理
GPT-5.1-Codex-Max的压缩机制(或称“紧缩”compaction)就是为了突破这个限制。它的工作原理可以类比为人类的“工作记忆管理”:
- 自动筛选:在长时间任务中,模型会自动组织历史内容,过滤掉冗余信息,只保留关键上下文。比如调试过程中的中间状态和无关日志会被省略,而错误信息和修复逻辑被保留。
- 跨上下文连贯性:即使处理数百万token,模型也能保持任务的连贯性,不会丢失上下文或遗失进度。
- 自主迭代:OpenAI内部测试显示,Codex-Max可以在长达24小时的任务中自主迭代代码、修复测试失败,最终交付可用的结果。
实际价值:从助手到工程师
这个技术突破的意义在于,它让AI从“代码补全助手”真正升级为“自主工程师”。你可以给它分配一个大型任务(比如“将这个遗留系统迁移到新框架”),然后让它自己去工作数小时甚至一整天,期间不需要人类干预。这对于大型项目重构、遗留系统迁移、深度bug修复等场景而言,是真正的效率革命。
另一个重要优化是token效率。在一些任务中,Codex-Max能够在使用少至30%token的情况下达到更高的准确率,这意味着更低的API成本和更快的响应速度。
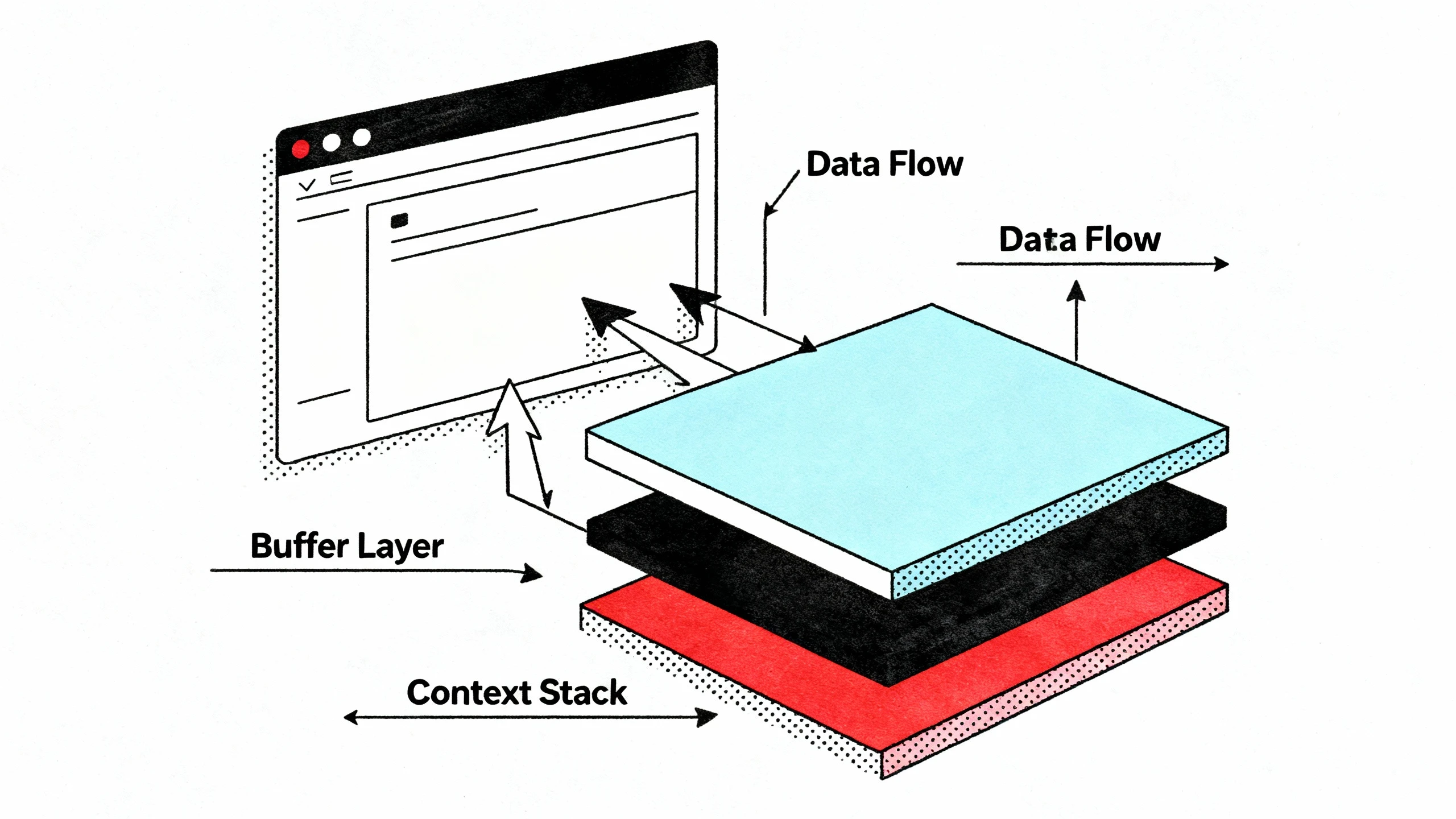
图2:GPT-5.1-Codex-Max的压缩机制通过自动上下文管理,实现数百万token的连续处理能力
性能实测:数据不会说谎
让我们看看具体的benchmark数据。在AI编码领域,主要有两个公认的金标准:SWE-bench和HumanEval。
SWE-bench Verified:真实工程能力测试
SWE-bench衡量AI解决真实GitHub issue的能力,是最接近实际软件工程场景的测试。这里的竞争非常激烈:Claude Sonnet 4.5得分77.2%领先,GPT-5.1-Codex-Max取得77.9%,GPT-5.1 Pro为76.3%,Gemini 3 Pro为76.2%。而开源模型DeepSeek R1得分51.7%,Llama 4 (405B)为46.9%。
GPT-5.1-Codex-Max在这个测试中取得77.9%的成绩,与前代GPT-5.1-Codex持平,但在token效率上有显著提升。这个分数表明,它在处理复杂代码库、理解上下文、生成修复bug的补丁方面已经达到行业顶尖水平。
Claude Sonnet 4.5在bug修复场景下表现突出,这说明它在针对现有代码库的精细化修复上有特别优势。相比之下,OpenAI的优势在于更广泛的适用性和生态成熟度。
HumanEval:代码生成能力
HumanEval测试模型根据描述生成功能正确代码的能力,共164道编程题。这个测试更偏重算法和问题解决能力:GPT-5.1 Pro领先以94.1%的成绩,Gemini 3 Pro为89.7%,Llama 4 (405B)为82.6%。
GPT-5.1 Pro在这个测试中占据绝对优势,94.1%的分数已经非常接近人类水平。这说明在从零开始的算法代码生成上,GPT系列仍然是最强的选择。
其他关键指标
在LiveCodeBench Pro的算法代码生成测试中,Gemini 3 Pro领先,Elo达到2439,比GPT-5.1高约200分。AIME 2025数学竞赛中,GPT-5.1 Pro和Gemini 3 Pro在启用代码执行时均为100%满分,纯推理模式下Gemini为95%、GPT为71%。而在MathArena Apex的高难度数学测试中,Gemini 3 Pro以23.4%大幅领先GPT-5.1的1.0%和Claude的1.6%。
如何解读这些数据?
在bug修复场景下,Claude Sonnet 4.5和GPT-5.1-Codex-Max并驾齐驱,都是顶尖选择。从零编码场景中,GPT-5.1 Pro在HumanEval上的表现说明它更适合算法题和新功能开发。数学推理方面,Gemini 3 Pro在高难度数学问题上占据优势,但GPT-5.1的工程化能力更全面。性价比方面,GPT-5.1-Codex-Max的token效率提升意味着在相同性能下成本更低,这对高频使用的API场景非常关键。
总的来说,OpenAI这次发布在编码领域守住了顶级位置,虽然在某些细分领域(如高难度数学)落后于Gemini,但其在工程化落地、生态完善度和开发者体验上仍然是最佳选择。
实战场景:这些能力对开发者意味着什么?
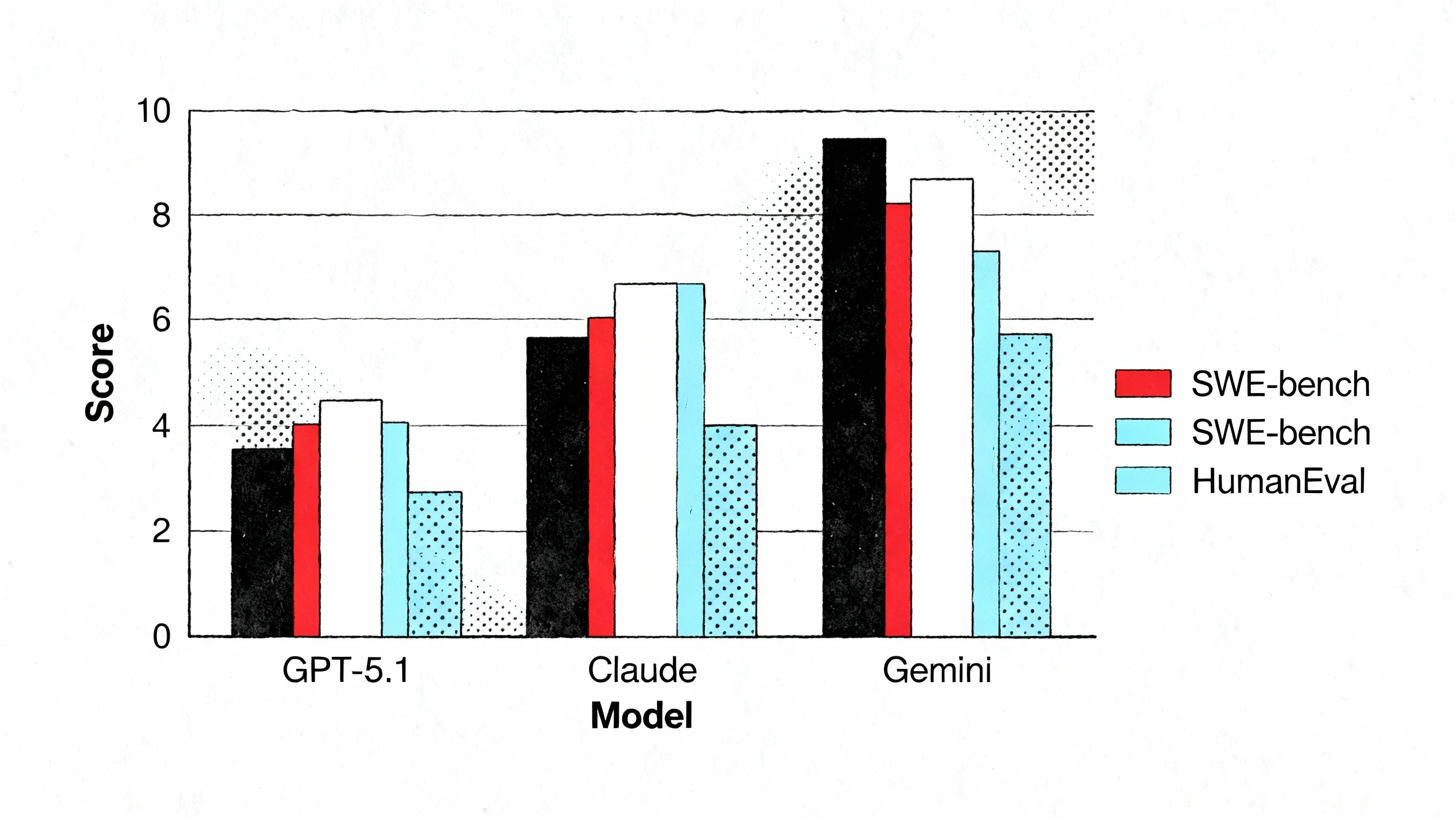
图3:主流AI编码模型在SWE-bench Verified和HumanEval基准测试中的性能对比数据
GPT-5.1系列的发布不是简单的参数升级,而是在实际工作流中带来具体的价值。以下是几个典型场景:
1. 大型项目重构
过去,将一个遗留系统迁移到新框架是一个耗时数周甚至数月的工程。现在有了GPT-5.1-Codex-Max,你可以让AI分析整个代码库结构,制定迁移计划并自动执行,在长达24小时的任务中保持上下文连贯,然后自动运行测试、修复问题、再次验证。
这能把一个需要团队几周才能完成的任务压缩到几天。
2. 深度调试与性能优化
对于复杂的bug或性能瓶颈,传统方式是开发者花费数小时甚至数天排查。Codex-Max可以读取整个项目的日志和调用链,进行多轮实验和假设验证,生成详细的性能分析报告,提供多种优化方案并自动测试。
这让开发者从“手动排查”变为“复查方案”。
3. 多仓库协同开发
现代软件项目往往涉及多个代码仓库(前端、后端、移动端等)。压缩机制让AI能够同时理解多个仓库的上下文,协调不同技术栈的API变更,确保端到端的一致性。
对于全栈开发者或小团队而言,这是真正的生产力解放。
4. 技术文档生成
GPT-5.1 Pro的高情商和高智商特性让它在文档生成上表现出色,能够阅读代码库并生成API文档,理解业务逻辑并编写架构文档,还能根据变更历史自动更新文档。
这能把开发者从“不想写文档”的痛苦中解放出来。
5. Windows生态支持
原生Windows支持意味着.NET、C#、Azure开发者现在可以无缝集成Visual Studio、使用Azure DevOps工作流、开发Windows桌面应用。
这填补了OpenAI在企业市场的一个重要空白。
总结:AI编码工具市场进入新阶段

图4:压缩机制让开发者能够将大型重构任务交给AI自主完成,实现真正的生产力解放
OpenAI这次同时发布GPT-5.1 Pro和GPT-5.1-Codex-Max,看似低调,实则在技术和产品层面都做出了关键突破。
核心亮点总结:
- 压缩机制是真正的游戏规则改变者。它让AI从“对话式助手”变为“自主工程师”,能够处理长达24小时的复杂任务而不丢失上下文。
- 性能数据证明实力。77.9%的SWE-bench Verified和94.1%的HumanEval成绩说明,OpenAI在编码领域仍然处于第一梯队。
- Windows原生支持打开了企业市场的新空间,为.NET和Azure开发者提供了更好的工具选择。
- Token效率提升让成本降低、速度提升,这对高频API调用场景至关重要。
竞争格局判断:
目前AI编码领域形成了三足鼎立的局面:
- OpenAI:生态成熟、工程化落地好、开发者体验优,适合大多数通用场景
- Anthropic(Claude):Bug修复和长期任务能力突出,适合复杂项目重构
- Google(Gemini):数学推理和多模态理解领先,但工程化体验仍有差距
给开发者的建议:
- 已有ChatGPT订阅的用户:直接升级到Pro版本,11月20日起即可使用Codex-Max。
- 需要长时间任务处理的团队:Codex-Max的压缩机制是为你设计的,适合项目重构、系统迁移。
- Windows/.NET开发者:原生支持意味着你现在是一等公民了,值得尝试。
- 关注API成本的开发者:Token效率提升30%意味着直接成本下降,适合高频调用场景。
AI编码工具的竞争远未结束,但OpenAI这次的发布证明,真正的技术突破比营销话术更有说服力。从对话式助手到自主工程师,这一步的跨越,或许正是我们一直在等待的那个质变。
发表评论
- No comments yet.
推荐的AI工具
精心选择的AI工具来改善您的工作,学习和生活效率。
相关文章

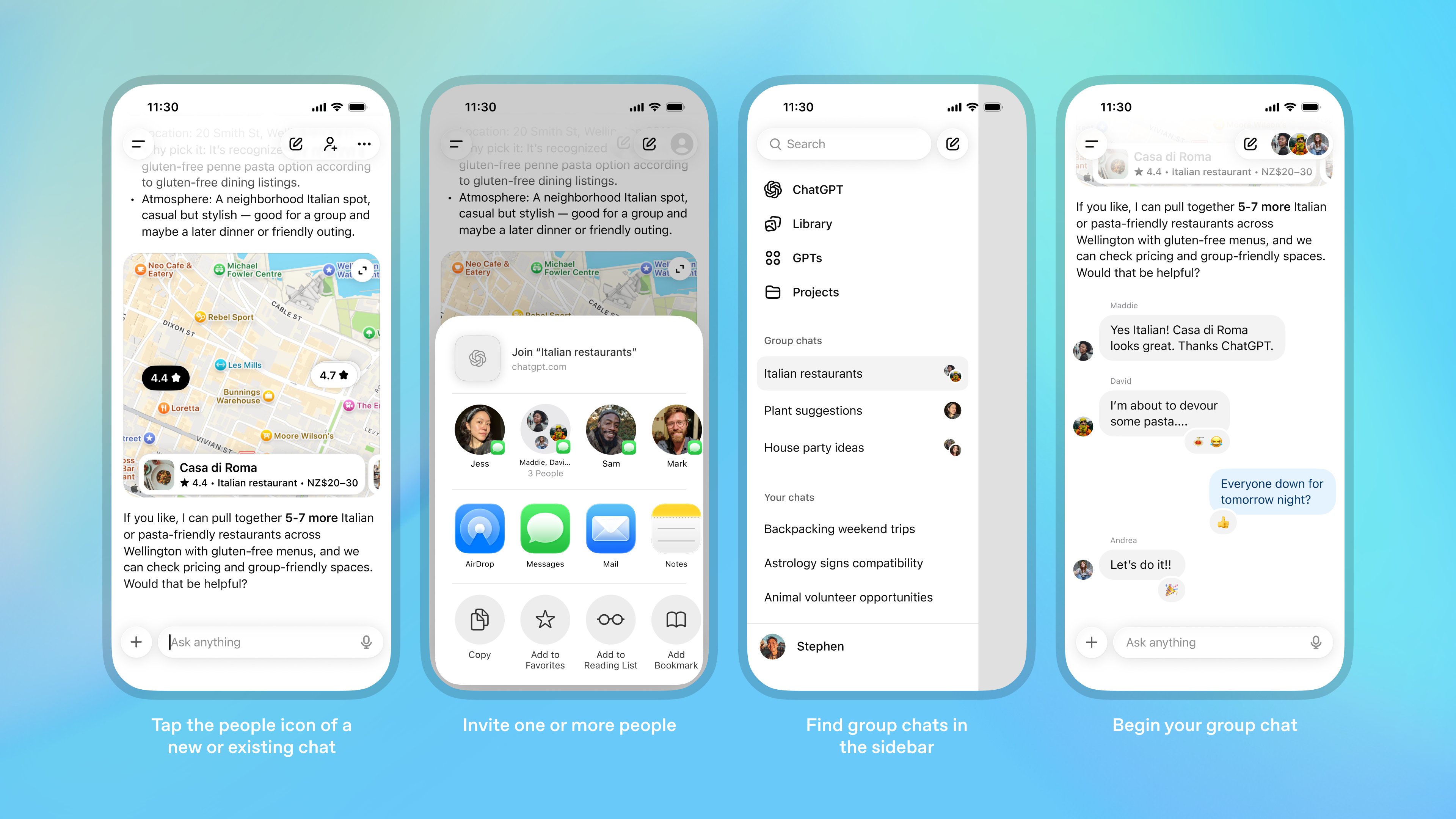
2025年11月14日,OpenAI正式开启ChatGPT群聊功能试点,标志着AI从个人助手迈向团队协作伙伴的重大转折
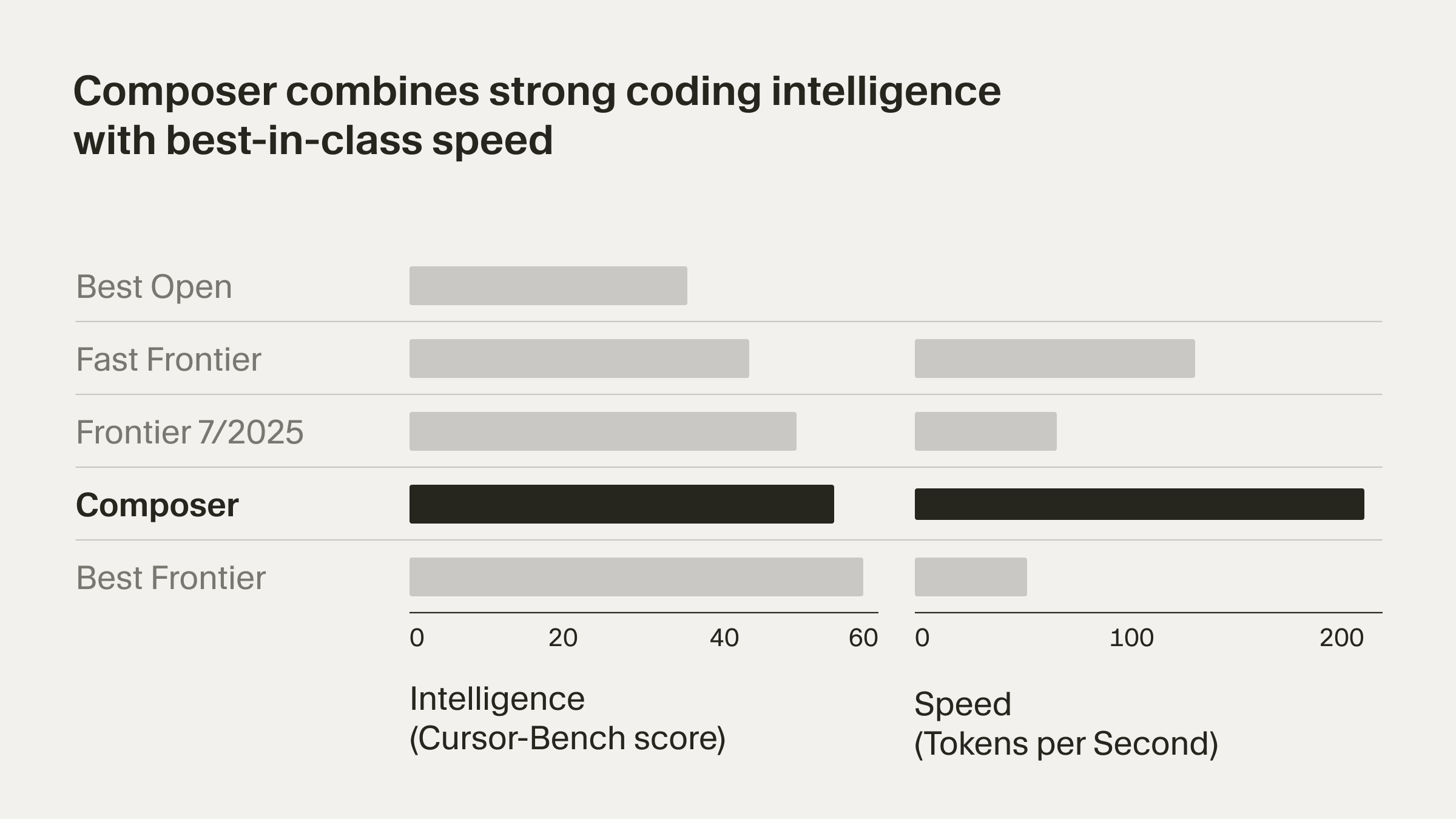
Cursor正式迈入2.0时代!其首个自研编程智能体模型Composer将响应速度提升4倍,更颠覆性地支持最多8个AI智能体并行协作。从此,你不再是代码的“打字员”,而是项目的“总指挥”。