はじめに
LPM 1.0は、画像や音声といったシンプルな入力からリアルタイムで表現豊かな動画を生成する、画期的なビデオベースのキャラクター演技モデルです。静止画を、双方向会話が可能な動きのある話すアバターへと変え、デジタルキャラクターに本物の命を吹き込みます。
LPM 1.0とは?
LPM 1.0は、Large Performance Model 1.0の略称です。これは、デジタルキャラクターのためのリアルタイム動画演技を生成するために特別に設計された先進的なAIモデルです。その中核的な解決課題は、AIを搭載したアバター、NPC、バーチャルエージェントをより人間らしく見せ、感じさせることです。単純なトーキングヘッドジェネレーターとは異なり、LPM 1.0は、自然な微表情、感情表現、長時間にわたるボディランゲージを含む、ニュアンスに富みアイデンティティに一貫性のある演技の生成に焦点を当てています。会話エージェントを作成する開発者、表現豊かなノンプレイヤーキャラクター(NPC)を必要とするゲームスタジオ、ライブ配信のためのコンテンツクリエイター、人間とコンピュータの相互作用を研究する研究者に適しています。フルデュプレックス会話(話す状態と聞く状態をシームレスに切り替える)動画を提供する能力は、より没入感があり自然なデジタルインタラクションへの重要な一歩です。
LPM 1.0の主な機能
アイデンティティの保持
LPM 1.0は、参照画像からのマルチグラニュラリティなアイデンティティ条件付けを使用することで、キャラクターが常に自分自身のように見えることを保証し、歯、表情の皺、横顔の形状などの細部を幻覚(ハルシネーション)なく保持します。
マルチモーダル制御性
このモデルは、動作のためのテキスト、感情と発話のための音声、キャラクター定義のための画像という3つの自然な入力を単一の生成パスで統合することで、きめ細かい演出制御を提供します。
キャラクター汎化性
フォトリアルな人間から2Dアニメ、3Dゲームモデル、さらには非ヒューマノイドの生き物まで、幅広いキャラクタースタイルの表現豊かな演技を、モデルのファインチューニングを一切必要とせずに生成できます。
長期安定性
無限のインタラクションのために構築されたそのオンラインストリーミングアーキテクチャは、数時間あるいは数日にわたって安定したアイデンティティ一貫性のある動画生成を維持し、時間経過による視覚的な劣化を防ぎます。
フルデュプレックス会話
LPM 1.0は、ライブ対話の全範囲を捉え、ユーザーの音声から適切な傾聴行動(うなずき、視線の移動)を、応答音声からはリアルタイムで正確な発話演技(リップシンク、身体のリズム)を生成します。
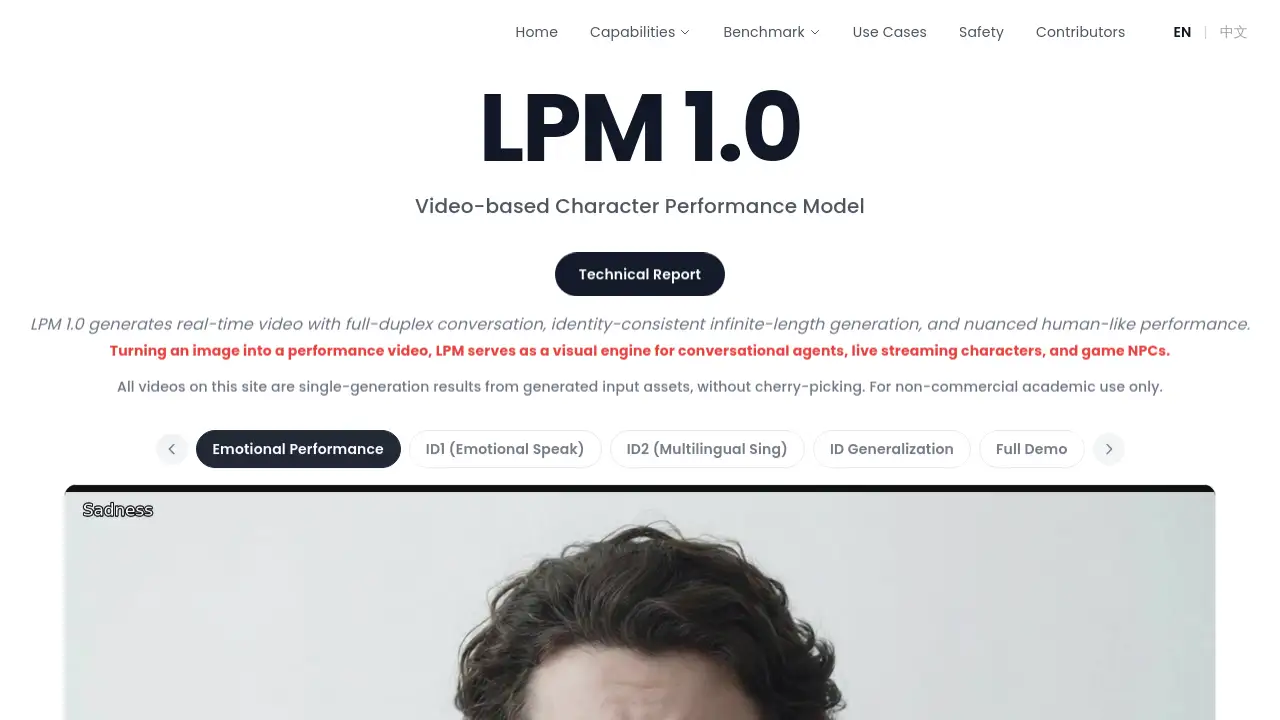
表現豊かな感情演技
このモデルは、微妙な微表情から悲しみ、恐怖、喜びなどの激しい感情表現まで、自然な演技と呼吸のリズムを伴った正確な感情表現を持つ動画の生成に優れています。
LPM 1.0のユースケース
会話型AIアバター
LPM 1.0は、AIチャットボットやバーチャルアシスタントのビジュアルエンジンとして機能し、リアルタイム会話中のユーザーエンゲージメントを高める、生き生きとした話す動画の存在感を提供します。
ゲームNPCとバーチャルインフルエンサー
ゲーム開発者やコンテンツクリエイターは、ノンプレイヤーキャラクターやライブ配信・インタラクティブストーリーテリングのためのデジタルインフルエンサーのために、表現豊かでアイデンティティに一貫性のある動画を生成するために使用できます。
インタラクティブ教育およびカスタマーサービスエージェント
このモデルは、教育用チューターやカスタマーサービスのボットを駆動することができ、現実的で感情に反応する動画アバターは、長期安定性のあるコミュニケーションとユーザー信頼の向上に寄与します。
プロトタイピングとコンテンツ制作
アニメーターや映像制作者は、シンプルな画像と音声入力を提供することで、キャラクター演技の迅速なプロトタイピングや動画コンテンツの生成が可能です。多様なスタイルに対応するそのキャラクター汎化性を活用できます。
LPM 1.0の使い方
- 入力を準備する: キャラクターの参照画像を用意します。オプションで、より良いアイデンティティ保持のために、異なる角度や表情の追加画像を提供します。駆動用の音声(発話や歌唱用)と、動作のための記述テキストを準備します。
- 音声モデルと統合する: フルデュプレックス会話のためには、LPM 1.0をChatGPTのような音声対音声(A2A)モデルに接続します。LPMは音声ストリームに基づいて動画生成を処理します。
- 生成モードを設定する: 会話の状態に基づいて、モデルを「発話(Speak)」、「傾聴(Listen)」、または「無音(Silence)」モードのどれにするかを指定します。対応する音声またはテキスト入力を提供します。
- 生成とストリーミング: モデルを実行します。LPM 1.0はマルチモーダル入力を処理し、結果のリアルタイム動画演技をストリーミングします。長時間セッションでは、そのアーキテクチャが長期安定性を保証します。
- アプリケーションに実装する: 生成された動画フィードを使用して、会話エージェント、ゲームキャラクター、またはライブ配信を駆動します。
LPM 1.0の対象ユーザー
- マルチモーダル生成や人間-AIインタラクションに焦点を当てるAIおよび機械学習研究者。
- 次世代のNPCやインタラクティブな物語を作成するゲーム開発者およびスタジオ。
- 会話型AIおよびバーチャルアシスタントプラットフォームの開発者。
- キャラクターを素早く動かすツールを探しているコンテンツクリエイターおよびアニメーター。
- メタバース、バーチャルリアリティ、デジタルヒューマン技術におけるアプリケーションを構築するテクノロジー企業。
LPM 1.0は無料ですか?
公式ウェブサイトによると、LPM 1.0は現在「非営利の学術目的でのみ」リリースされています。これは通常、商用価格プランが立ち上げ時点では利用できない、研究に焦点を当てたリリースを示しています。商用アプリケーションに興味のあるユーザーは、将来のライセンスやAPI提供に関するアップデートについて、公式プロジェクトページを注視する必要があります。
| プラン | 価格 | 特徴 |
|---|---|---|
| 学術/非営利 | 無料 | 研究、テスト、非営利プロジェクトのためのモデルへのアクセス。 |
| 商用 | 未提供 | 商用ライセンスの詳細は後日発表予定。 |
LPM 1.0の長所と短所
| 側面 | 長所 | 短所 |
|---|---|---|
| パフォーマンス品質 | 卓越したアイデンティティ保持と感情表現力。高忠実度のリアルタイム動画生成。 | パフォーマンスは入力参照画像と音声の品質に依存する。 |
| 技術 | 自然な傾聴行動を伴うフルデュプレックス会話を可能にする。多様なスタイルにわたる強力なキャラクター汎化性。 | 現在は非営利利用に限定されており、ビジネスアプリケーションが制限される。 |
| 使いやすさ | 互換性のある音声モデルと共に、プラグアンドプレイのビジュアルエンジンとして機能する。 | 完全な会話機能のためには(A2Aモデルのような)他のAIシステムとの統合が必要。 |
| 持続性 | 無限長インタラクションにおける長期安定性のために設計されている。 | オンラインデモでは、注記されているように、状態切り替え時にわずかな音声-動画同期の問題が発生する可能性がある。 |
LPM 1.0に関するよくある質問
LPM 1.0が動画を生成するには、どのような入力が必要ですか?
LPM 1.0は、マルチモーダル入力を使用するビデオベースのキャラクター演技モデルです。最低限、キャラクターの参照画像1枚と音声クリップが必要です。最良の結果を得るためには、追加の参照画像と、キャラクターの動作や表情を導く記述テキストプロンプトも提供できます。
LPM 1.0はどんなキャラクタースタイルの動画も生成できますか?
はい、その中核機能の一つがキャラクター汎化性です。フォトリアルな人間、2Dアニメ、3Dゲームキャラクター、さらには動物などの非ヒューマノイドの生き物まで、モデルのファインチューニングなしで演技を生成できます。
LPM 1.0はリアルタイム会話をどのように処理しますか?
リアルタイム会話では、LPM 1.0は音声モデルと連携して動作します。ユーザーの音声を受信すると、傾聴表情を持つストリーミング動画を生成します。AIモデルの応答音声が送り返されると、LPMは発話演技の生成に切り替えます。無音の瞬間には、アイドル行動の生成を続け、フルデュプレックス会話を可能にします。
生成された動画は長時間安定していますか?
はい、LPM 1.0は特に長期安定性のために設計されています。そのオンラインストリーミングフレームワークは、ライブインタラクションに不可欠な、長時間(潜在的に無限長)の生成にわたって一貫したキャラクターアイデンティティと視覚的品質を維持するように設計されています。
LPM 1.0の主な制限は何ですか?
現在の主な制限は、非営利学術目的のみのライセンスです。技術的には、そのサイトで注記されているように、対話デモでは、音声トラック分離のエラーにより、発話-傾聴の切り替え時に音声と動画の間で短い同期の問題が発生する可能性があります。
LPM 1.0は発話のみに機能しますか、それとも歌唱も扱えますか?
LPM 1.0は、発話と歌唱の両方を含む音声演技のために設計されています。その「発話ストリーム」は、歌唱音声にビジーム(視覚的な発音記号)と上半身のリズムを合わせることができ、キャラクターが自然に歌っているように見える演技を作り出します。
LPM 1.0 タグ
LPM 1.0, ビデオベースキャラクター演技モデル, リアルタイム動画生成, フルデュプレックス会話, AIアバター, デジタルヒューマン, キャラクターアニメーション, アイデンティティ一貫性生成, 会話型AI, ゲームNPC, ライブ配信キャラクター, 感情的AI, マルチモーダルAI, 長期安定動画, AIパフォーマンスモデル