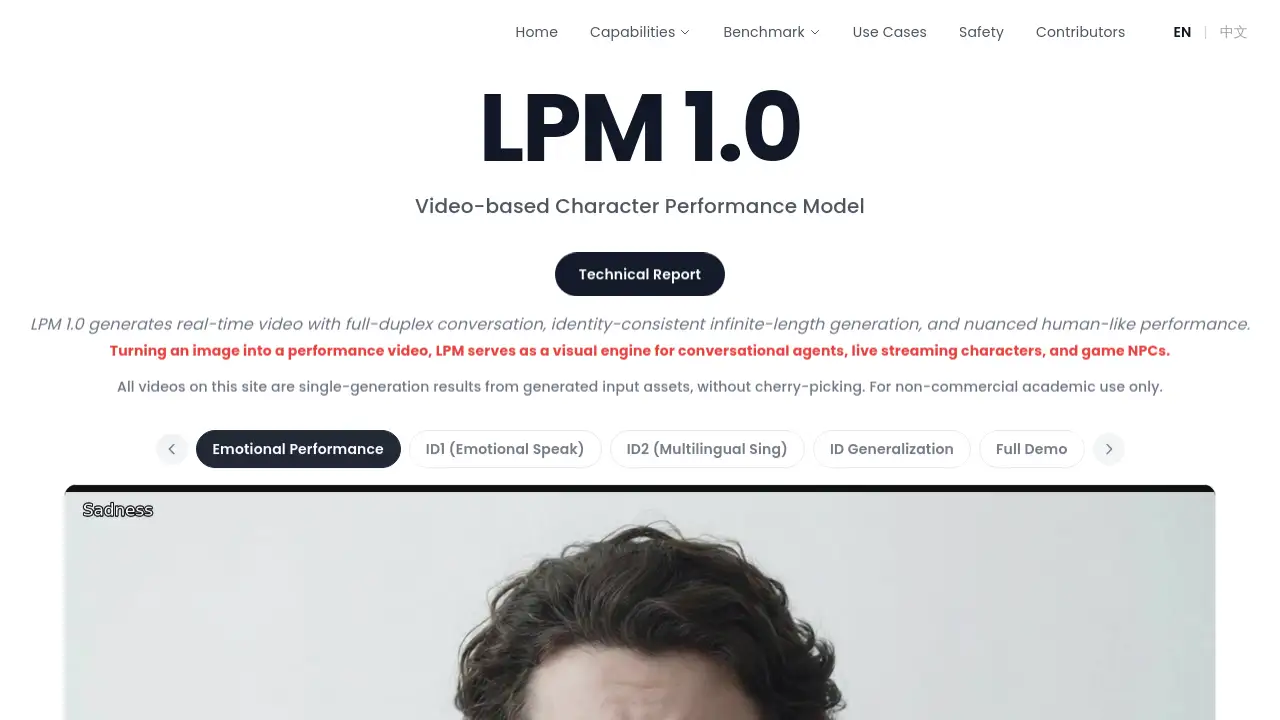
Introduction
LPM 1.0 is a groundbreaking video-based character performance model designed to generate real-time, expressive video from simple inputs like an image and audio. It turns static pictures into dynamic, talking avatars capable of full-duplex conversation, making digital characters feel genuinely alive.
What is LPM 1.0?
LPM 1.0 stands for Large Performance Model 1.0. It is an advanced AI model specifically engineered to generate real-time video performances for digital characters. The core problem it solves is making AI-powered avatars, NPCs, and virtual agents look and feel more human. Unlike simple talking-head generators, LPM 1.0 focuses on creating nuanced, identity-consistent performances with natural micro-expressions, emotional delivery, and body language over extended periods. It is suitable for developers creating conversational agents, game studios needing expressive non-playable characters (NPCs), content creators for live streaming, and researchers in human-computer interaction. Its ability to provide full-duplex conversation video—seamlessly switching between speaking and listening states—makes it a significant step toward more immersive and natural digital interactions.
Key Features of LPM 1.0
Identity Preservation
LPM 1.0 ensures characters look consistently like themselves by using multi-granularity identity conditioning from reference images, preserving fine details like teeth, expression wrinkles, and profile geometry without hallucination.
Multimodal Controllability
The model offers fine-grained directorial control by unifying three natural inputs: text for action, audio for emotion and speech, and images for character definition, all within a single generation pass.
Character Generalization
It can generate expressive performances for a wide range of character styles—from photorealistic humans to 2D anime, 3D game models, and even non-humanoid creatures—without requiring any model fine-tuning.
Long-term Stability
Built for endless interaction, its online streaming architecture maintains stable and identity-consistent video generation over hours or even days, preventing visual degradation over time.
Full-Duplex Conversation
LPM 1.0 captures the full spectrum of live dialogue, generating appropriate listening behaviors (nods, gaze shifts) from user audio and precise speaking performances (lip sync, body rhythm) from response audio in real time.
Expressive Emotional Performance
The model excels at generating videos with accurate emotional delivery, from subtle micro-expressions to intense displays of feelings like grief, fear, or joy, accompanied by natural acting and breathing rhythms.
Use Cases for LPM 1.0
Conversational AI Avatars
LPM 1.0 serves as a visual engine for AI chatbots and virtual assistants, providing them with a lifelike, talking video presence that enhances user engagement during real-time conversation.
Game NPCs and Virtual Influencers
Game developers and content creators can use it to generate expressive, identity-consistent video for non-playable characters or digital influencers for live streaming and interactive storytelling.
Interactive Educational and Customer Service Agents
The model can power educational tutors or customer service bots, where a realistic, emotionally responsive video avatar can improve communication and user trust over long-term stability.
Prototyping and Content Creation
Animators and filmmakers can rapidly prototype character performances or generate video content by providing simple image and audio inputs, leveraging its character generalization for diverse styles.
How to Use LPM 1.0
- Prepare Your Inputs: Gather a reference image of your character. Optionally, provide additional images from different angles or with different expressions for better identity preservation. Prepare your driving audio (for speaking or singing) and any descriptive text for actions.
- Integrate with an Audio Model: For full-duplex conversation, connect LPM 1.0 with an audio-to-audio (A2A) model like ChatGPT. LPM will handle the video generation based on the audio streams.
- Configure the Generation Mode: Specify whether the model should be in 'Speak', 'Listen', or 'Silence' mode based on the conversation state. Provide the corresponding audio or text input.
- Generate and Stream: Run the model. LPM 1.0 will process the multimodal inputs and stream the resulting real-time video performance. For long sessions, its architecture ensures long-term stability.
- Implement in Your Application: Use the generated video feed to power your conversational agent, game character, or live stream.
Target Audience for LPM 1.0
- AI and Machine Learning Researchers focusing on multimodal generation and human-AI interaction.
- Game Developers and studios creating next-generation NPCs and interactive narratives.
- Developers of Conversational AI and virtual assistant platforms.
- Content Creators and Animators looking for tools to quickly animate characters.
- Tech Companies building applications in metaverse, virtual reality, and digital human technology.
Is LPM 1.0 Free?
Based on the official website, LPM 1.0 is currently released "For non-commercial academic use only." This typically indicates a research-focused release with no commercial pricing plans available at launch. Users interested in commercial applications should monitor the official project page for future licensing or API availability updates.
| Plan | Price | Features |
|---|---|---|
| Academic/Non-commercial | Free | Access to the model for research, testing, and non-commercial projects. |
| Commercial | Not Available | Commercial licensing details are to be announced. |
LPM 1.0's Pros and Cons
| Aspect | Pros | Cons |
|---|---|---|
| Performance Quality | Exceptional identity preservation and emotional expressiveness. High-fidelity real-time video generation. | Performance is dependent on the quality of input reference images and audio. |
| Technology | Enables full-duplex conversation with natural listening behaviors. Strong character generalization across diverse styles. | Currently limited to non-commercial use, restricting business applications. |
| Usability | Functions as a plug-and-play visual engine with compatible audio models. | Requires integration with other AI systems (like A2A models) for complete conversational functionality. |
| Longevity | Designed for long-term stability in infinite-length interactions. | The online demo may exhibit minor audio-video sync issues at state handoffs, as noted. |
Frequently Asked Questions about LPM 1.0
What kind of input does LPM 1.0 need to generate a video?
LPM 1.0 is a video-based character performance model that uses multimodal inputs. At a minimum, it requires a single reference image of the character and an audio clip. For best results, you can also provide additional reference images and descriptive text prompts to guide the character's actions and expressions.
Can LPM 1.0 generate videos of any character style?
Yes, one of its core features is character generalization. It can generate performances for photorealistic humans, 2D anime, 3D game characters, and even non-humanoid creatures like animals, all without any model fine-tuning.
How does LPM 1.0 handle a real-time conversation?
For real-time conversation, LPM 1.0 works in tandem with an audio model. It generates a streaming video with listening expressions when it receives user audio. When the AI model's response audio is sent back, LPM switches to generating a speaking performance. In moments of silence, it continues generating idle behavior, enabling full-duplex conversation.
Is the generated video stable for long durations?
Yes, LPM 1.0 is specifically architected for long-term stability. Its online streaming framework is designed to maintain consistent character identity and visual quality over extended, potentially infinite-length generations, which is crucial for live interactions.
What are the main limitations of LPM 1.0?
The main current limitation is its license, which is for non-commercial academic use only. Technically, as noted on its site, in dialogue demos, errors in audio track separation can cause brief sync issues between audio and video at speak-listen handoffs.
Does LPM 1.0 only work for speaking, or can it handle singing too?
LPM 1.0 is designed for vocal performance, which includes both speaking and singing. Its "speak stream" can align visemes and upper-body rhythm to sung audio, creating performances where characters appear to be singing naturally.
LPM 1.0 Tags
LPM 1.0, video-based character performance model, real-time video generation, full-duplex conversation, AI avatar, digital human, character animation, identity-consistent generation, conversational AI, game NPC, live streaming character, emotional AI, multimodal AI, long-term stable video, AI performance model