Kimi Linear emerges: revolutionizing the attention architecture of Transformer, boosting long text processing efficiency by 6 times.
On October 31, 2025, Moonshot AI officially released its new hybrid linear attention architecture, Kimi Linear. This is not only a technological iteration but also potentially a cornerstone technology for the development of next-generation AI agents.
Bottlenecks of Traditional Transformers: Why a New Attention Architecture is Needed?
The traditional Transformer architecture, with its powerful attention mechanism, laid the foundation for the development of large language models over the past five years. However, with the expansion of AI applications, especially towards agents and long text understanding, the bottlenecks of the traditional architecture have become increasingly apparent.
The core problem of the traditional Transformer lies in its quadratic time complexity—when the sequence length increases tenfold, the computational cost increases one hundredfold. Simultaneously, during autoregressive generation, the Key-Value Cache (KV Cache) grows linearly with the sequence length, consuming significant GPU memory resources.
This means that traditional methods are computationally infeasible when processing long texts with millions of tokens. This is the fundamental motivation behind the Moonshot AI team's proposal of Kimi Linear.
Kimi Linear's Core Innovations: Three Major Technological Breakthroughs
2.1 Kimi Delta Attention (KDA): A Refined Gating Mechanism
The core of Kimi Linear is a novel linear attention module called Kimi Delta Attention (KDA). Compared to previous methods, KDA introduces a fine-grained diagonal gating mechanism.
Simply put, traditional linear attention acts like a "one-size-fits-all" gatekeeper, applying the same forgetting rate to all information. KDA, however, equips each information feature dimension with an independent "gatekeeper," allowing for more precise decisions on which key information to retain and which redundant content to forget. This design enables KDA to more accurately regulate its limited RNN state memory, selectively retaining key information and forgetting irrelevant noise.
2.2 3:1 Hybrid Architecture: A Golden Balance of Efficiency and Performance
Kimi Linear employs an innovative hybrid architecture design, alternating KDA layers with full attention layers (MLA) in a 3:1 ratio. That is, one full attention layer is inserted after every three KDA linear attention layers.
The Dark Side of the Moon team discovered through extensive experimentation that this ratio represents the "sweet spot" for achieving the optimal balance between performance and efficiency. A ratio higher than this leads to a decrease in model performance, while a ratio lower than this fails to fully realize the efficiency advantages.
This design allows Kimi Linear to maintain global information flow through the full attention layer when generating long sequences, while reducing memory and KV cache usage by up to 75%.
2.3 Hardware Optimization and No-Position Encoding (NoPE)
All full attention layers in Kimi Linear do not use any explicit positional encoding (NoPE). The considerations behind this design choice are profound. The model completely delegates the responsibility of encoding positional information to the KDA layer, while the global attention layer can focus on pure content association.
In terms of hardware optimization, KDA employs a specially designed block-processing parallel algorithm, significantly improving computational efficiency. This makes KDA's operator efficiency approximately 100% higher than standard DPLR.
Performance Testing: Outperforming Traditional Solutions in Every Way
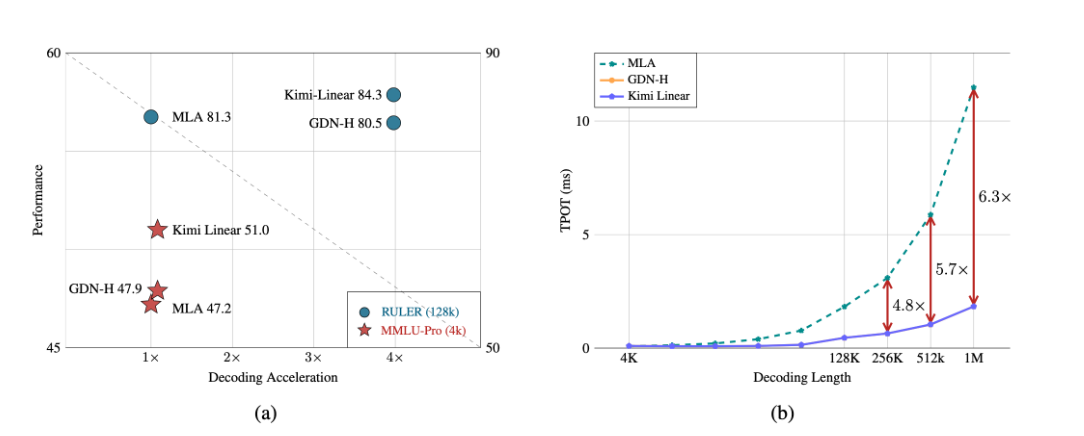
3.1 Performance Comparison Data
The table below summarizes the comparison results of Kimi Linear and traditional architectures on key metrics:
| Performance Metrics | Traditional Full Attention Model (MLA) | Kimi Linear | Improvement |
|---|---|---|---|
| Decoding Throughput (1M tokens) | 11.48ms/token | 1.84ms/token | 6.3x Improvement |
| KV Cache Usage | Baseline | Reduced by 75% | Significantly Reduced |
| Long Context Performance (RULER) | 81.3 points | 84.3 points | Significant Improvement |
| General Knowledge (MMLU-Pro) | 47.2 points | 51.0 points | Comprehensive Leadership |
3.2 Multi-Scenario Performance Advantages
According to the technical report, under the same training conditions (1.4 trillion tokens pre-trained, 48 billion total parameters, 3 billion activation parameters), Kimi Linear demonstrates comprehensive advantages in multiple authoritative benchmark tests:
Short Context Tasks: Kimi Linear achieves leading scores across general knowledge benchmarks such as MMLU, BBH, and HellaSwag.
Long Context Understanding: It achieved top scores in benchmarks like RULER with 128K context lengths, demonstrating its superior long text information retrieval and association capabilities.
Mathematical and Coding Abilities: It leads in mathematical and coding reasoning tasks such as GSM8K, MATH, and CRUXEval.
Reinforcement Learning: In reinforcement learning tasks requiring multi-step reasoning, Kimi Linear demonstrates faster convergence speeds and higher final performance.
Practical Implications for AI Developers
4.1 Reducing the Cost of Long Text Processing
Kimi Linear's significantly reduced KV caching means that longer documents, such as legal contracts, academic papers, and codebases, can be processed with fewer hardware resources. This can significantly reduce computational costs for enterprise applications that need to process extremely long texts.
4.2 Accelerating the Development of AI Agents
The Kimi Linear architecture is particularly well-suited for AI agent applications requiring long-sequence inference. Traditional AI agents face significant computational challenges in long-term planning and decision-making, while Kimi Linear's efficiency advantages provide a feasible technical foundation for complex decision-making tasks.
4.3 Open Source Ecosystem and Ease of Use
Moonshotai has open-sourced the core code of its KDA kernel and released pre-trained model checkpoints (such as moonshotai/Kimi-Linear-48B-A3B-Instruct) on platforms like Hugging Face, which developers can immediately download and experience. The mainstream inference acceleration framework vLLM has also announced support for the Kimi Linear architecture, facilitating its deployment in real-world production environments.
In-depth Analysis of the Technical Architecture
5.1 How Kimi Delta Attention Works
KDA is a novel variant of gated linear attention, based on Gated DeltaNet (GDN) with key improvements. Its core innovation is the introduction of fine-grained diagonal gating, replacing the scalar forget gate in GDN. From a mathematical perspective, the state transitions of KDA can be viewed as a special type of diagonally-plus-low-rank (DPLR) matrix. This structure allows KDA to achieve high hardware computation while maintaining expressiveness through a customized block-parallel algorithm.
5.2 Design Philosophy of Hybrid Architecture
The 3:1 hybrid ratio is not arbitrarily chosen, but rather a "golden ratio" verified through extensive experiments. Research has found that:
. 7:1 ratio: While computationally more efficient, model performance significantly decreases.
. 1:1 ratio: Stable performance, but no significant speed advantage.
. 3:1 ratio: Achieves the optimal balance between efficiency and performance.
This design embodies the idea of "specialized division of labor": the KDA layer is responsible for efficient local information processing, while the full attention layer periodically integrates global information.
Future Outlook and Industry Impact
The launch of Kimi Linear marks a new stage in the development of large models, shifting the focus from simply "stacking parameters" to "optimizing the underlying structure." As one researcher put it, "This is just an intermediate stage; ultimately, we are still moving towards achieving infinite context models."
For the industry as a whole, Kimi Linear demonstrates that linear attention architectures can not only improve efficiency but also enhance model performance, potentially influencing the future architectural design of large models. More companies and research teams may turn to linear attention research, driving the entire field towards greater efficiency.
Conclusion
The emergence of Kimi Linear is not merely a technological breakthrough, but also points the way forward for the entire industry. Efficiency and performance can coexist; the key lies in innovation in the underlying architecture.
For AI developers, it is recommended to familiarize themselves with this architecture as soon as possible, as it is likely to become a cornerstone technology for the next generation of AI applications. With mainstream inference frameworks such as vLLM having announced support for the Kimi Linear architecture, this technology will soon be widely adopted in various AI applications.
The development of AI is no longer just about "bigger," but about "smarter"—and Kimi Linear is a key catalyst for this transformation.
Project Address
HuggingFace Model Library: https://huggingface.co/moonshotai/Kimi-Linear-48B-A3B-Instruct
Technical Paper: https://github.com/MoonshotAI/Kimi-Linear/blob/master/tech_report.pdf
Kimi Linear represents a wave of innovation in AI infrastructure, and the entire AI tool ecosystem is evolving at an unprecedented pace. To help you stay updated on cutting-edge tools like Kimi Linear and gain insights into industry trends, please bookmark our site: https://aiwith.me/
Leave your comment
- No comments yet.
Recommended AI Tools
Carefully selected AI tools to improve your work, study, and live efficiency.
Related Articles
A major breakthrough has been achieved in the core architecture of large-scale models! The release of Kimi Linear marks the first time that linear attention technology has comprehensively surpassed and significantly outperformed the traditional Transformer full-attention model in both performance and efficiency. This "win-win" achievement is expected to significantly reduce the computational barriers and costs for long text processing, complex reasoning, and AI agent applications, potentially changing the competitive landscape of underlying technologies for large-scale models.

Over the past week, the AI community's attention has been drawn to a mysterious model that quietly emerged on the OpenRouter platform—Polaris Alpha. As a direct continuation of yesterday's discussion of the GPT-5.1 leak, this suddenly appearing model brings more technical details and strategic signals worthy of in-depth exploration.

A new paradigm in knowledge acquisition has arrived, this time powered by AI.

Standing at this moment in 2025, when we look back at the development journey of artificial intelligence, we witness how this revolutionary technology has reshaped every aspect of human society. From initial theoretical concepts to today's practical applications, each step forward in AI technology has changed the way we live. Let's revisit this fascinating journey together.