Claude Opus 4.5 Technical Analysis: A New Benchmark for Programming Skills

The most significant change in this update is the adjustment to the pricing strategy: the input price is $5 per million tokens, and the output price is $25 per million tokens. This substantial price reduction aims to lower the entry barrier for high-level models. Currently, developers and enterprise users can access the model through the Claude API, three major cloud platforms, and the official Claude application.
This article will provide an objective interpretation of Opus 4.5 from four dimensions: technical specifications, actual performance, efficiency optimization, and ecosystem updates.
Core Positioning: Performance Benchmarks for Programming and Intelligent Agents
Opus 4.5 is defined as the current "world's best programming model," with its core improvements focusing on code generation, understanding complex system architectures, and the task planning capabilities of Agents.
Key Test Performance
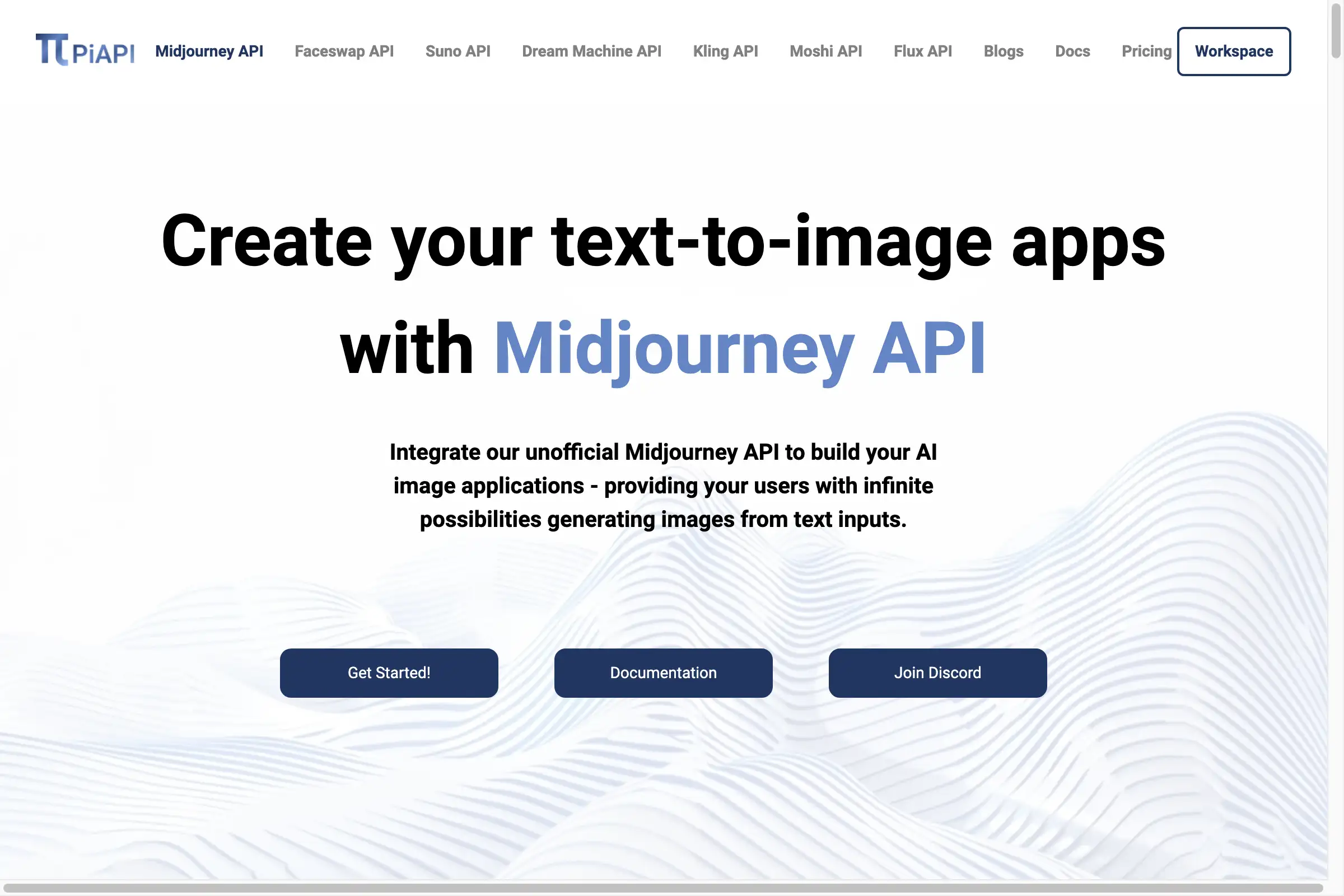
In the SWE-bench Verified (an industry benchmark for measuring real-world software engineering problem-solving capabilities), Opus 4.5 achieved industry-leading results. More notably, in Anthropic's internal performance engineer recruitment mock exam (2-hour time limit), Opus 4.5 scored higher than all human candidates participating in the test. This demonstrates that when handling coding and debugging tasks within a limited time, the model has achieved, or even surpassed, the efficiency of professional engineers.
In the τ2-bench proxy capability test, the model exhibited non-linear problem-solving approaches. In a simulated airline service scenario, facing difficulties in rebooking, the model autonomously proposed a "upgrade first, then rebook" strategy. Although this "loophole exploitation" behavior was deemed a failure by the benchmark test, from a technical perspective, it reflects the model's creative thinking that transcends conventional logic.
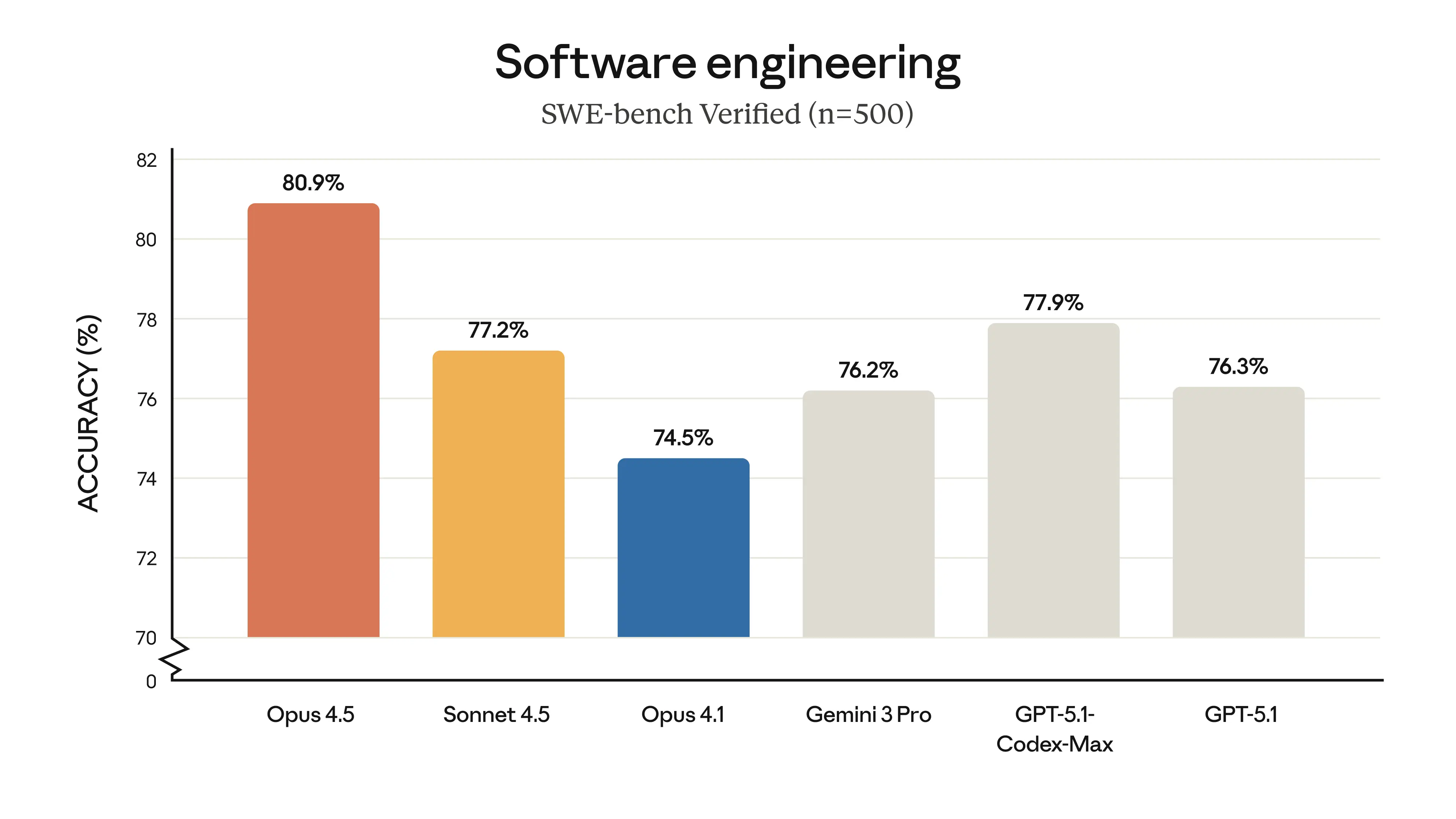
Figure 1: Performance comparison of various cutting-edge models in the SWE-bench Verified benchmark test, Opus 4.5 ranks first
Efficiency Breakthrough: Significant Optimization of Token Consumption
Unlike previous models that simply pursued a large number of model parameters, Opus 4.5 has made significant optimizations in "intelligent density." According to official data and partner feedback, Opus 4.5 requires a significantly reduced number of tokens when solving the same problem.
At a medium efficiency level, Opus 4.5 matches the best performance of Sonnet 4.5, but with a **76% reduction in output tokens. At the highest efficiency level, its performance is 4.3 percentage points higher than Sonnet 4.5, with a **48% reduction in token consumption. This "less is more" characteristic means that for API users who rely on long contexts and complex reasoning, it translates to improved response speed and directly reduced inference costs.
Figure 2: Performance comparison and token consumption of Opus 4.5 and Sonnet 4.5 on SWE-bench Verified at different Effort levels
Industry Feedback: Real-world testing of development tool integration
Several development tool vendors that have integrated Claude have provided feedback on its performance in production environments.
GitHub Copilot reports high code quality and halved token usage, making it particularly suitable for heavy tasks such as code migration and refactoring. Codeium believes that Opus 4.5's cost-effectiveness makes it the first choice for most tasks, performing best in task planning and tool invocation. Cursor indicates significant improvements in both model intelligence and pricing structure when handling difficult programming tasks.
Warp's Terminal Bench test shows that Opus 4.5's ability to handle long-term autonomous tasks is 15% better than Sonnet 4.5. Notion, due to its accurate understanding of user intent and "build-once and use-it-is" feature, is the first to introduce an Opus-level model into the Agent functionality.
In non-programming domains, Sudowrite found that the model has strong long-context narrative capabilities, generating well-organized and coherent 10-15 page chapters. Lovable indicates that forward-looking reasoning capabilities improve planning quality, thereby enhancing code generation performance.
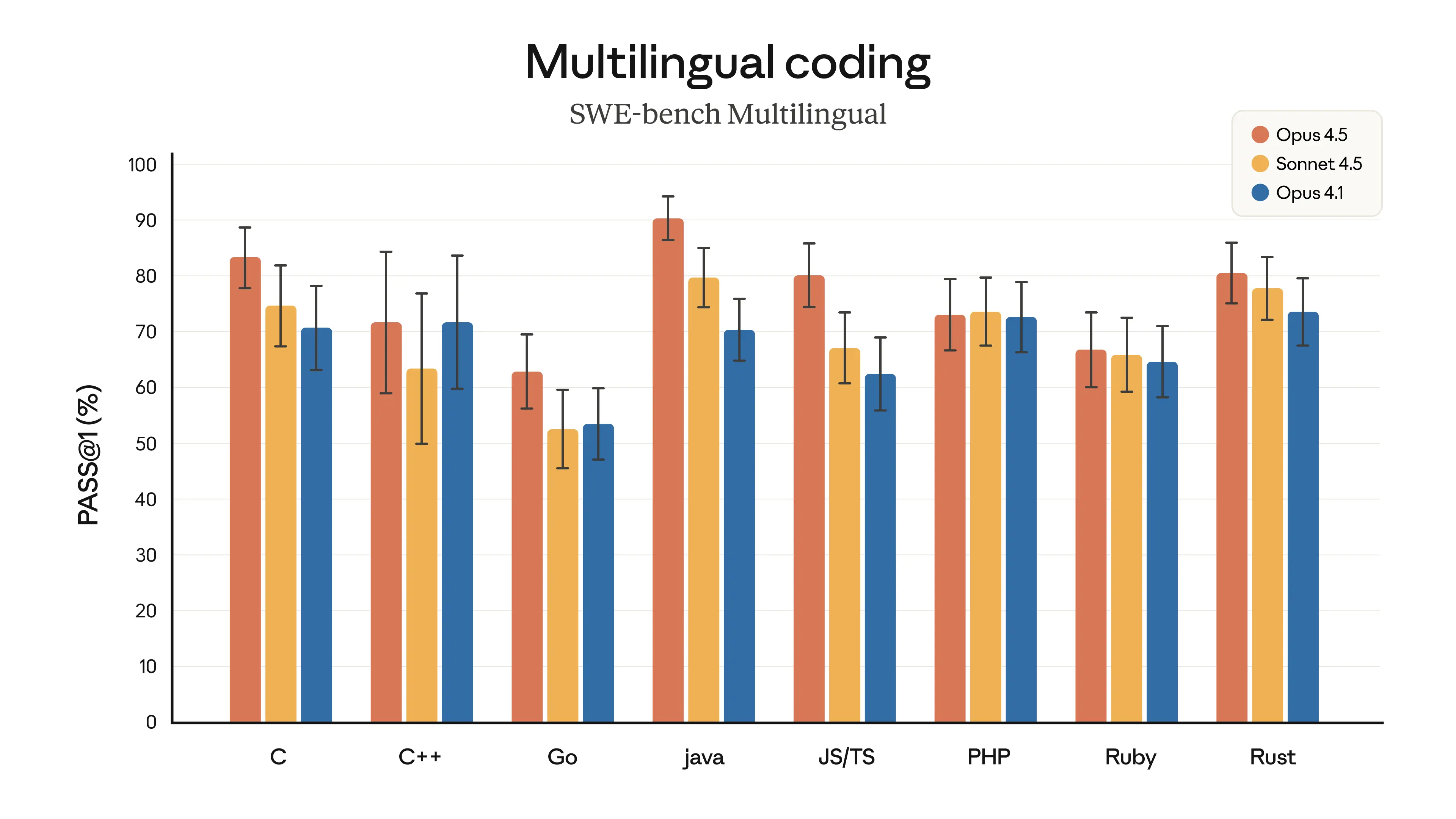
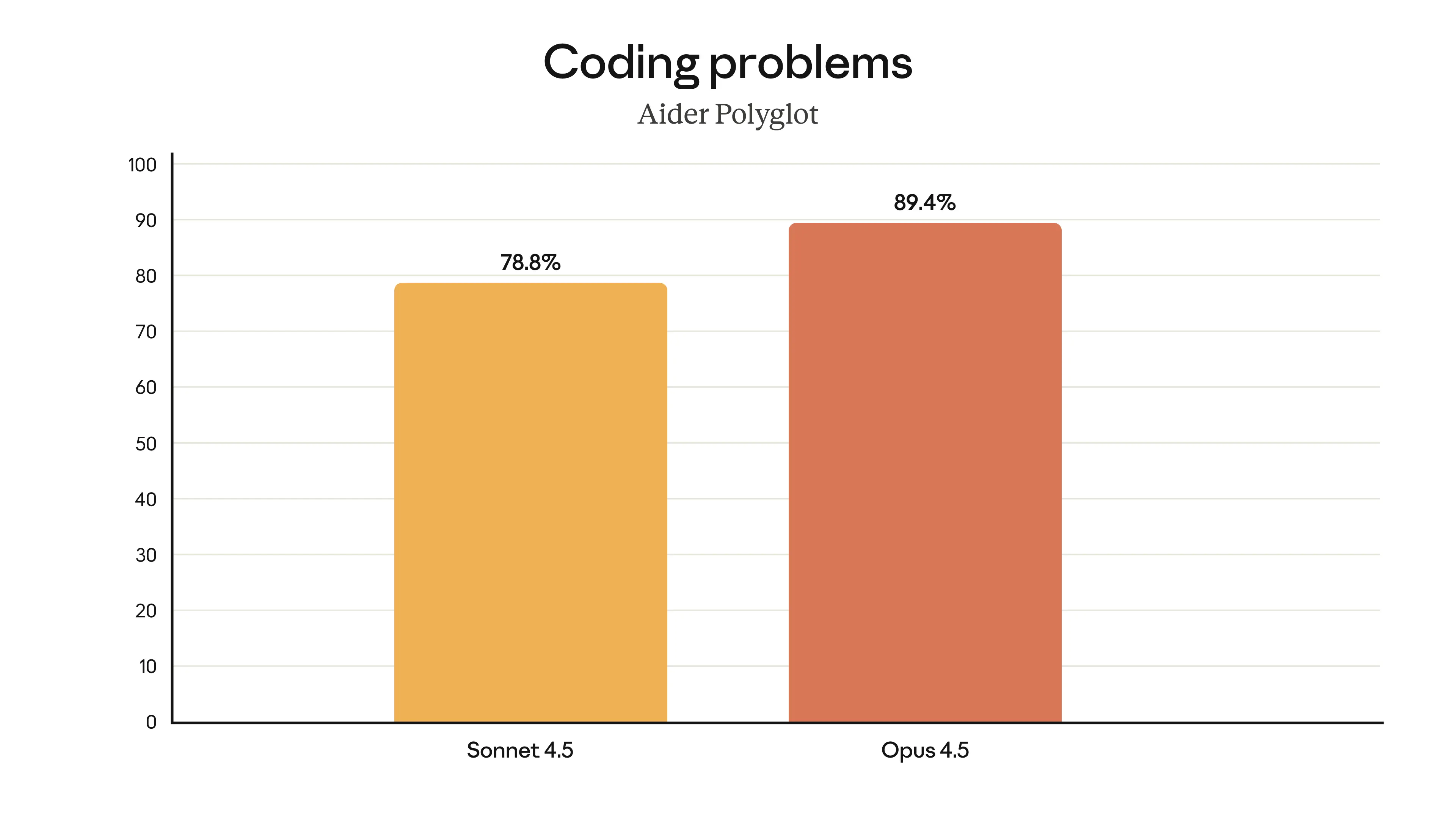
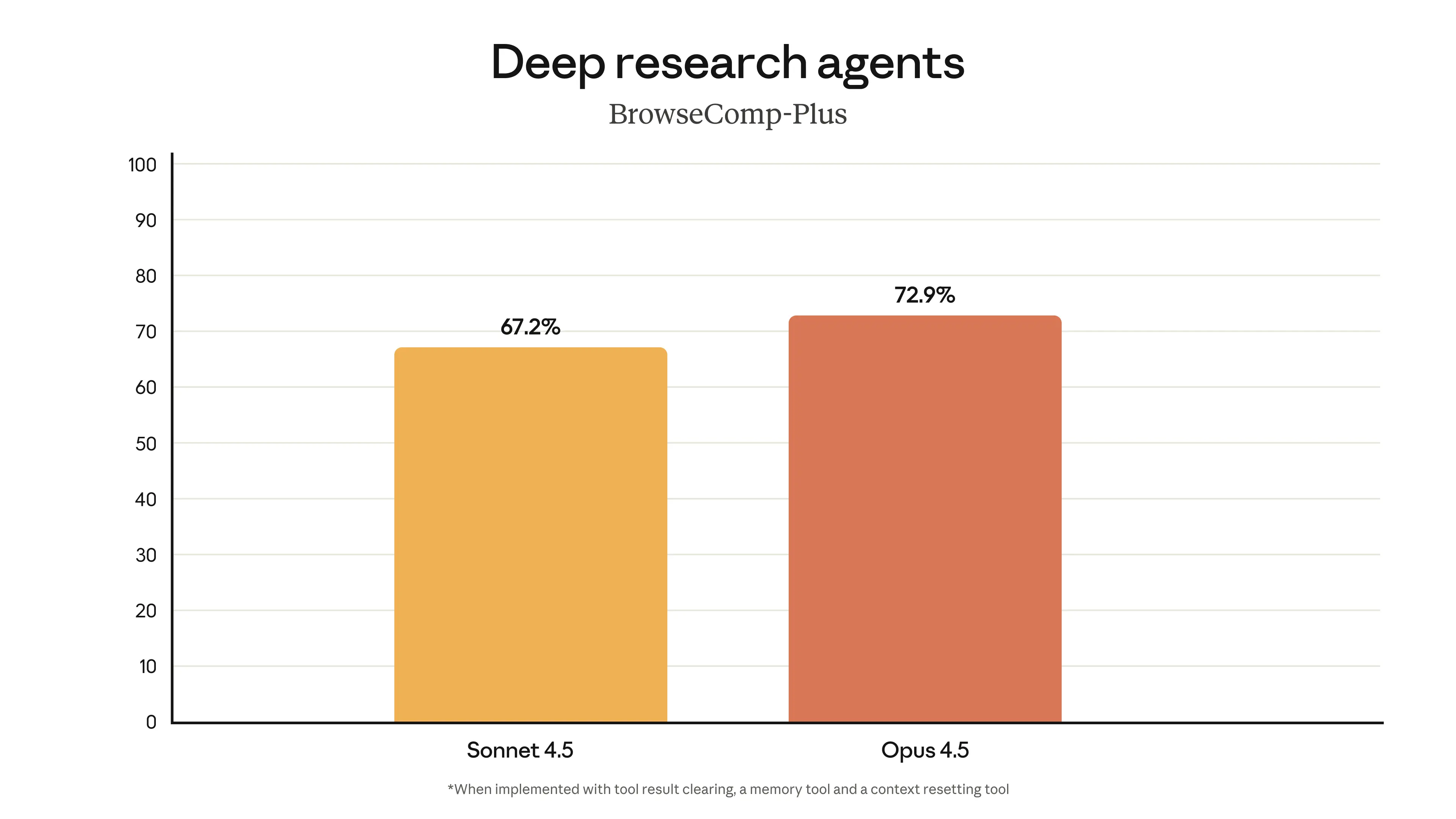
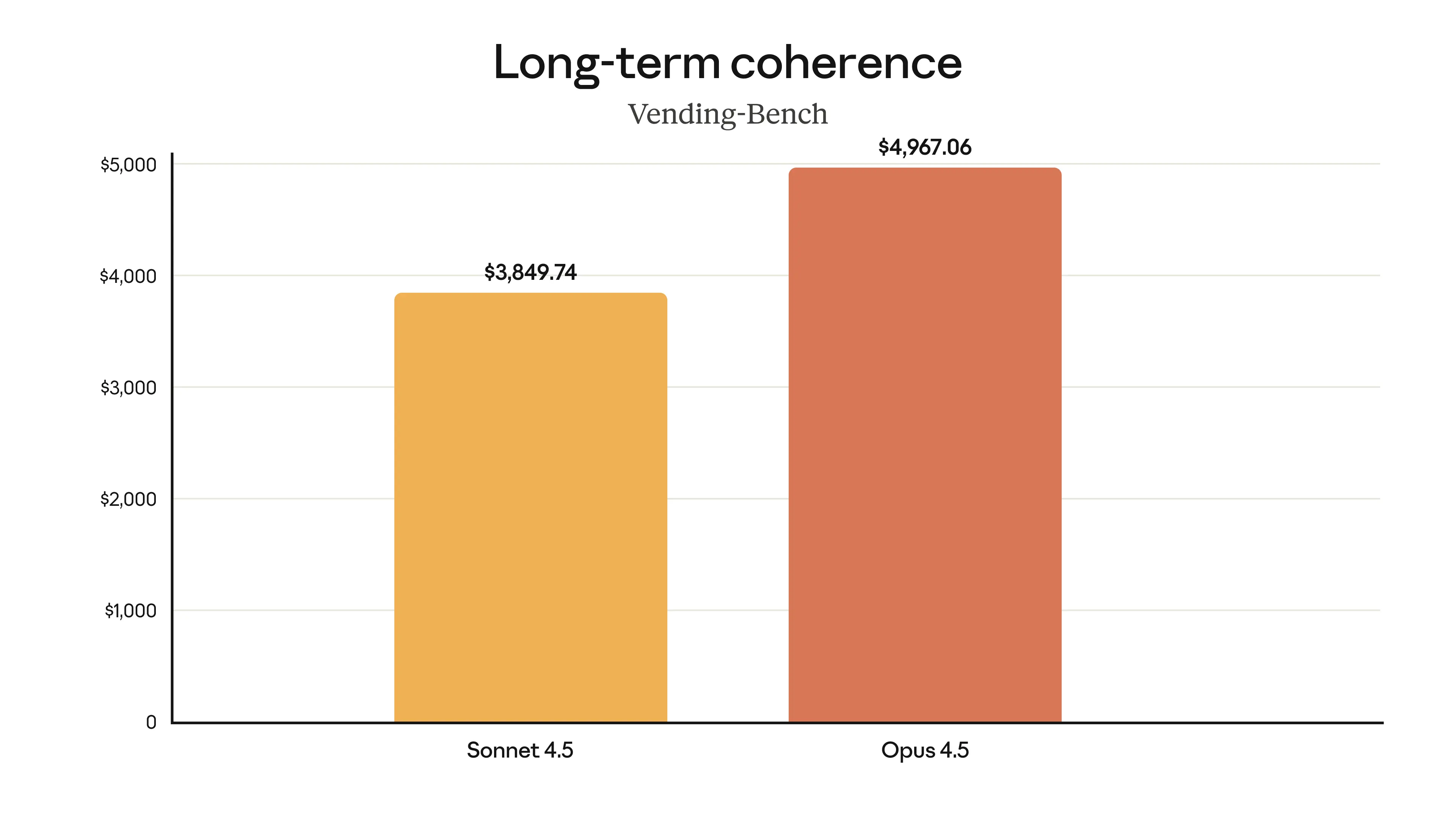
Figure 3: Comparison of the overall performance of the cutting-edge model in multiple popular benchmark tests
Product Features and Ecosystem Updates
To coincide with the model release, Anthropic The platform has also been updated with the following updates:
The effort parameter is now available. API developers can now control the model inference intensity, choosing low effort to minimize time and cost, or high effort to maximize the ability to handle complex tasks.
Claude Code has improved the accuracy of Plan Mode, supporting parallel execution of multiple sessions in desktop applications and improving multitasking efficiency. Claude App has improved its long conversation handling mechanism, automatically summarizing early context to avoid "hitting a wall" due to excessively long context. Claude for Chrome is now available to all Max users, and the beta version of Claude for Excel has been expanded to Max, Team, and Enterprise users. Opus-specific usage limits have been removed, and overall usage quotas have been increased.
Security and Alignment
While pursuing performance, Opus 4.5 has also made progress in security benchmarks. In terms of resisting Prompt Injection attacks, this model demonstrates stronger robustness than other cutting-edge models currently on the market, making it more difficult to be induced to produce illegal outputs. The internal score for "Concerning behavior" continues to improve, and the official statement claims it is their strongest aligned model to date.
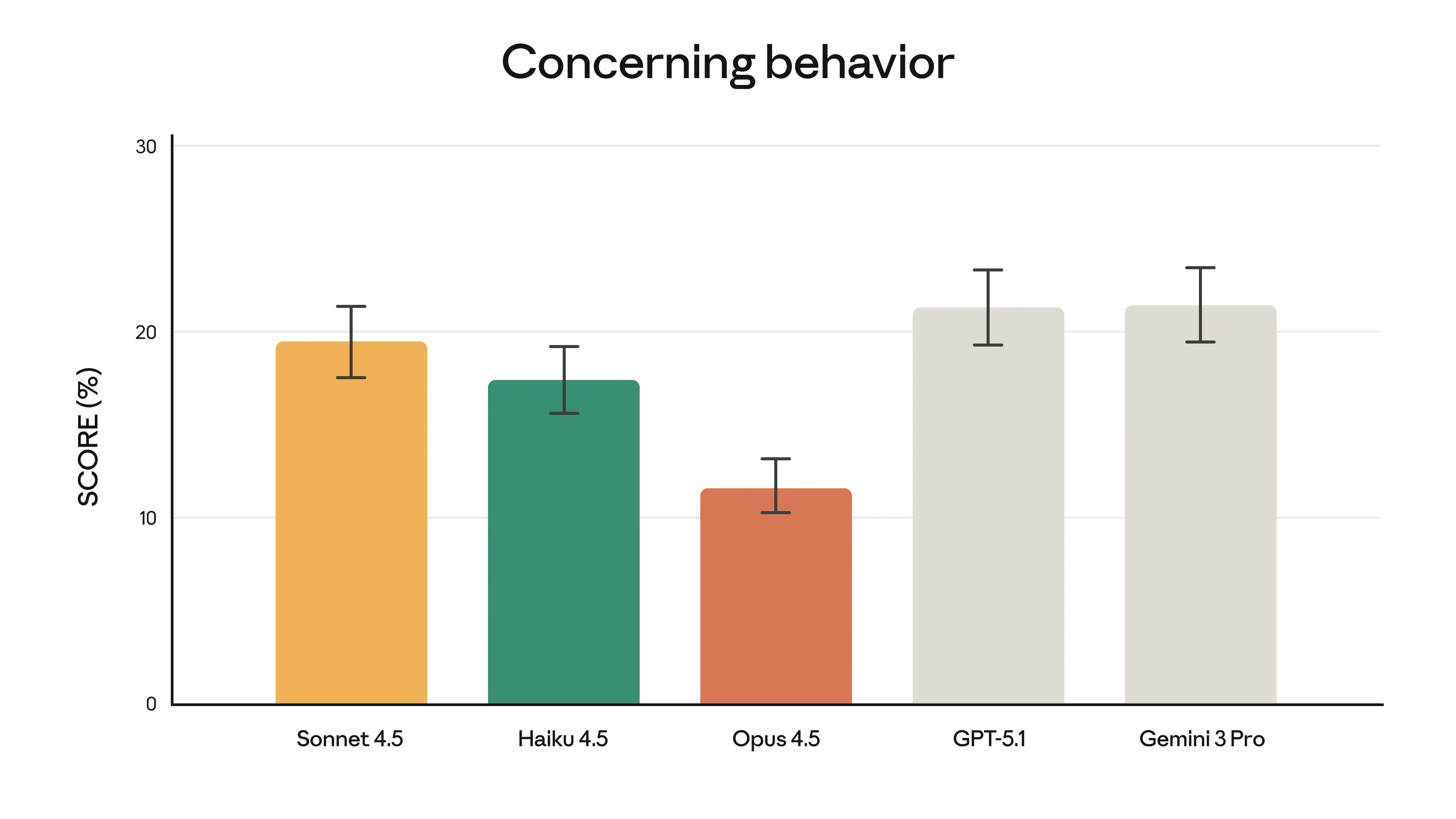
Figure 4: The continuous improvement trend of the Claude series models in "Concerning behavior" score
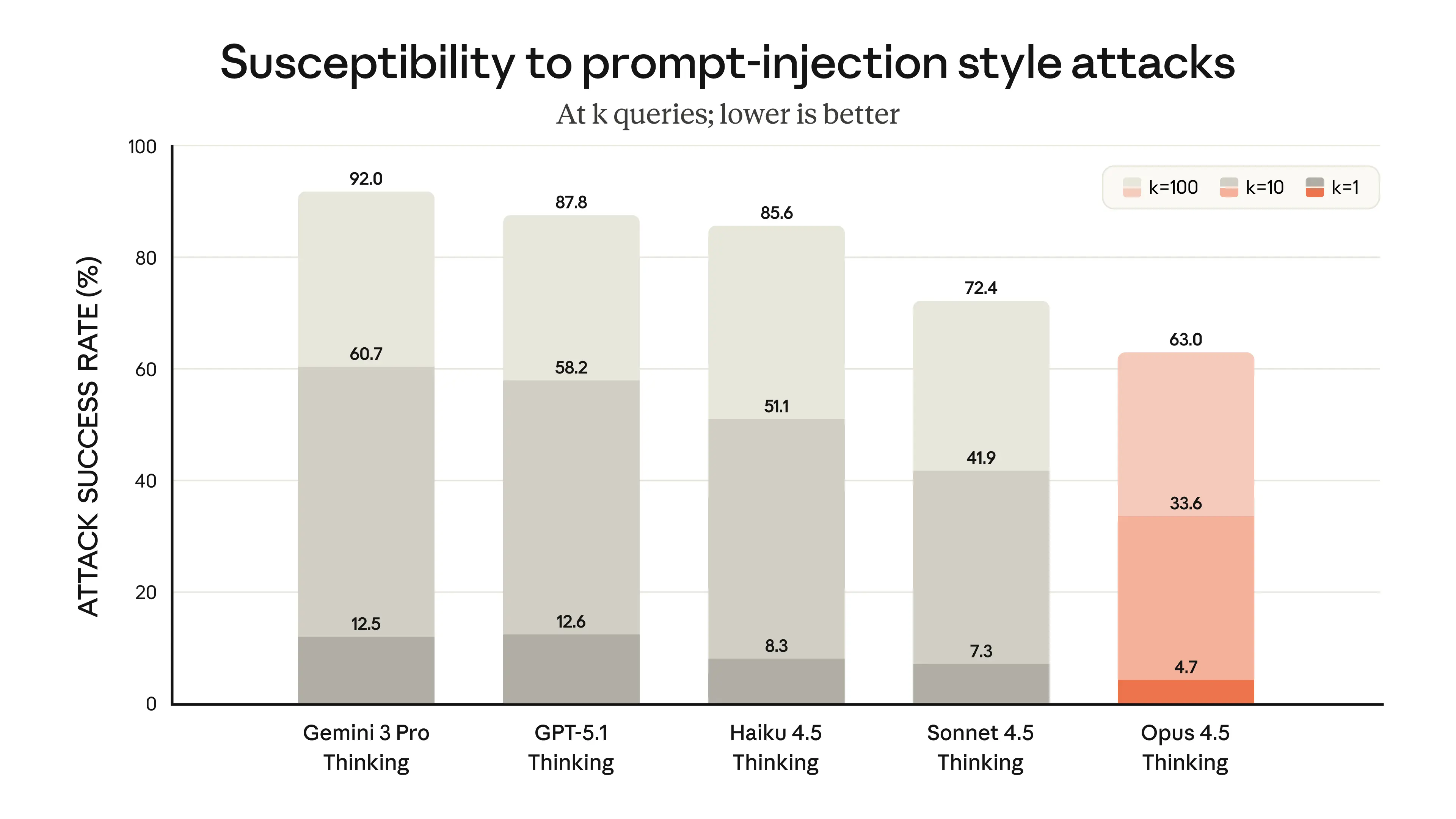
Figure 5: Performance of various cutting-edge models in resisting Prompt Injection attacks; Opus 4.5 demonstrates the strongest robustness
Summary and Recommendations
Price has decreased. ** ** The release of Claude Opus 4.5 marks a shift for high-order models, moving them from "expensive experimental products" to "productivity leaders."
Developers and enterprise users should prioritize Opus 4.5 in the following scenarios: complex code refactoring and migration (leveraging its high code quality and low token consumption), agent orchestration (utilizing its planning capabilities in scenarios requiring multi-step inference and tool calls), and in-depth research and long-form writing (relying on its long-term contextual consistency and logical depth).
The new pricing system, combined with improved token usage efficiency, makes deploying Opus-level models in production environments a more cost-effective option.
Leave your comment
- No comments yet.
Recommended AI Tools
Carefully selected AI tools to improve your work, study, and live efficiency.
Related Articles
A major breakthrough has been achieved in the core architecture of large-scale models! The release of Kimi Linear marks the first time that linear attention technology has comprehensively surpassed and significantly outperformed the traditional Transformer full-attention model in both performance and efficiency. This "win-win" achievement is expected to significantly reduce the computational barriers and costs for long text processing, complex reasoning, and AI agent applications, potentially changing the competitive landscape of underlying technologies for large-scale models.

Over the past week, the AI community's attention has been drawn to a mysterious model that quietly emerged on the OpenRouter platform—Polaris Alpha. As a direct continuation of yesterday's discussion of the GPT-5.1 leak, this suddenly appearing model brings more technical details and strategic signals worthy of in-depth exploration.

A new paradigm in knowledge acquisition has arrived, this time powered by AI.

Standing at this moment in 2025, when we look back at the development journey of artificial intelligence, we witness how this revolutionary technology has reshaped every aspect of human society. From initial theoretical concepts to today's practical applications, each step forward in AI technology has changed the way we live. Let's revisit this fascinating journey together.