DeepSeek V3.2 - A Dual Evolution of Reasoning and Agent Capabilities

DeepSeek released version 3.2 yesterday, along with a Speciale version. This update differs from previous minor version iterations, focusing on two key areas: inference capabilities and agent-based scenarios. After reviewing the technical report, I think a few points are worth discussing.
src="https://www.youtube.com/embed/EX_gPbb_M7E"
width="100%"
height="450"
frameborder="0"
allow="accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture"
allowfullscreen>
In conclusion: V3.2 can now perform on par with GPT-5 in tasks requiring deep inference, such as mathematics and programming. The Speciale version has even achieved gold medal levels in top-tier competitions like the IMO and IOI. More importantly, the model is completely open source.
Efficiency issues in long text processing have been resolved
The most crucial change in V3.2 is the attention mechanism. Traditional Transformers face a major challenge when processing long text: their computational complexity is O(L²), and the computational cost increases quadratically with longer context. This directly impacts inference speed and cost.
DeepSeek's solution is called DSA (DeepSeek Sparse Attention). The principle is simple: a lightweight indexer quickly selects the k most important tokens for each token, and then attention is calculated only on these k tokens. This reduces the complexity from O(L²) to O(Lk).
The indexer itself has minimal computational overhead, requiring only a few attention heads, and can run with FP8 precision, resulting in a significant overall efficiency improvement. Official data shows that when processing 128K context on an H800 cluster, the token cost in V3.2 is significantly lower than the previous generation, especially during the prefilling stage.
This improvement has a direct impact on practical use: in scenarios such as long document analysis and large-scale codebase processing, inference speed is faster and cost is lower.
- BrowseComp: 51.4% (without context management), 67.6% (with context management strategy)
Increased Investment in Reinforcement Learning
V3.2's computational investment in the post-training phase exceeded 10% of the pre-training cost. This percentage is not common among open-source models.
Tool Use:
They still use the GRPO algorithm, but made several engineering optimizations to ensure stability during large-scale training. For example, they corrected the estimation method of KL divergence to avoid gradient instability; masked off-policy sequences to prevent excessive policy deviation; and maintained consistency in the expert routing of the MoE model during training and inference. These may seem like details, but they are crucial in large-scale RL training.
- MCP-Universal: 45.9%
The results show that as the RL training time increases, the model's performance on complex inference tasks does indeed continue to improve. This also verifies a trend: the improvement of inference ability increasingly depends on the computational investment in the post-training phase.
Breakthrough in Agent Capabilities
V3.2 is DeepSeek's first model to integrate inference capabilities into tool calls. While this sounds simple, its implementation presents numerous challenges.
- Summary: Summarize existing trajectories and restart when exceeding 80% of the context.
The core question is: how to enable the model to maintain deep thinking while using tools? DeepSeek's solution is to first teach the model to call tools during inference through carefully designed system prompts, and then synthesize training data on a large scale.
The data synthesis aspect is quite robust. They built over 1800 synthetic environments, generating 85,000 complex tasks:
Search Agent: Samples long-tail knowledge points from the internet, generates question-answer pairs, and then verifies the correctness of the answers using search tools. This ensures data quality.
Discard-all is more efficient, achieving an accuracy of 67.6% with fewer steps.
Code Agent: Mines tens of thousands of issue-PR pairs from GitHub and automatically builds executable environments. The selection criteria are strict: there must be a clear bug description, verifiable test cases, and a workable fix. It covers mainstream languages such as Python, Java, JavaScript, C/C++, Go, and PHP.
General Agent: A fully synthetic environment. For example, in a travel planning task, a relevant database is first generated, then a set of specialized tool functions are synthesized, and finally, the task and automatic verification function are generated. The design of the verification function is ingenious: the task itself has a large search space (e.g., it needs to satisfy multiple constraints), but verification is simple (just check the constraints once).
These synthetic data are not just filler. They conducted ablation experiments: running top-tier models like GPT-5 and Gemini 3.0 Pro on 50 synthetic tasks, only about 50-60% passed. DeepSeek-V3.2-Exp (the base model for generating the data) only achieved about 10%. This shows that the tasks are indeed challenging.
- Claude Sonnet 4.5: 34%
More importantly, it demonstrates good generalization ability. Using the SFT checkpoint of V3.2 on synthetic data for RL, there is a significant improvement in real-world benchmarks. This proves that the gap between the synthetic environment and real-world scenarios is not large.
How Does It Perform in Real-World Situations?
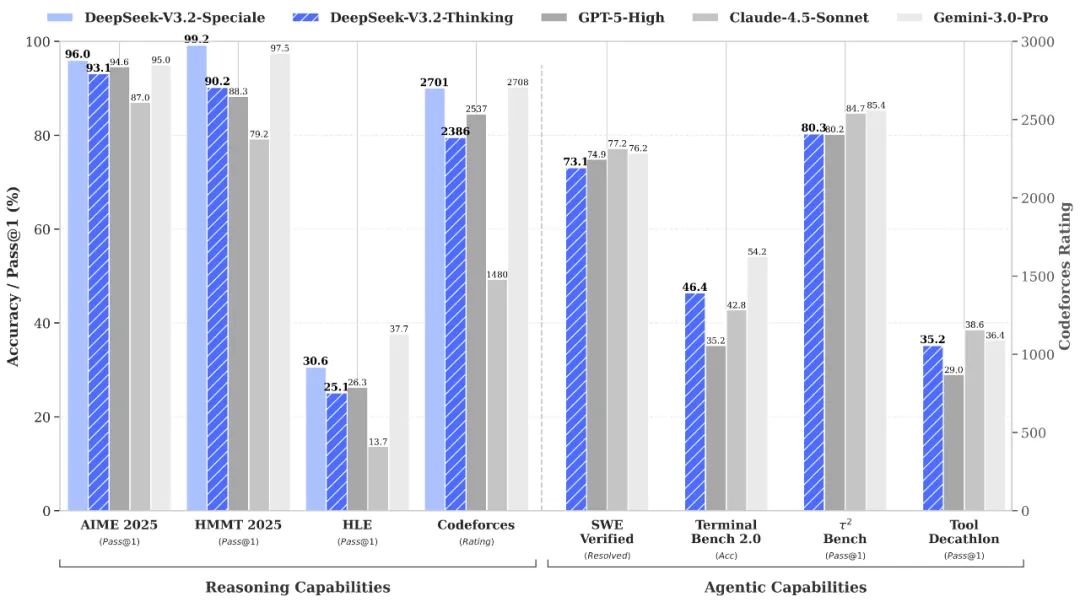
In math and programming tasks, V3.2 is basically on par with GPT-5-High: AIME 2025 accuracy is 93.1% (GPT-5 is 94.6%), LiveCodeBench is 83.3% (GPT-5 is 84.5%), and Codeforces rating is 2386 (GPT-5 is 2537).
The Speciale version performs even better: AIME 96%, LiveCodeBench 88.7%, and Codeforces rating 2701. It scored 35 points (out of 42) in IMO 2025, 492 points (out of 600) in IOI 2025, and solved 7 problems at the ICPC World Finals, all at gold medal level.
However, token efficiency is an issue. Speciale requires approximately 20,000 tokens to achieve 96% accuracy on AIME, while Gemini 3.0 Pro achieves 95% accuracy with only 15,000 tokens. This is the price of long reasoning—deeper thinking, but also more verbose.
Comparison of V3.2 with GPT-5, Gemini 3.0 Pro, and Claude Sonnet 4.5 in multiple tasks
In agent-related tests, V3.2 significantly narrowed the gap between open-source and closed-source. SWE-Verified (bug fixes in the actual code repository) 73.1%, close to GPT-5's 74.9%. SWE-Multilingual (multi-language code fixes) 70.2%, even exceeding GPT-5's 55.3%.
Regarding tool calls, τ²-bench 80.3%, MCP-Universal 45.9%, Tool-Decathlon 35.2%. While not quite on par with top-tier closed-source models like Gemini 3.0 Pro, it's quite good considering it's an open-source model.
V3.2 supports using the thinking mode in tool calls. Documentation link: https://api-docs.deepseek.com/guides/thinking_mode
A minor issue: V3.2 frequently performs redundant self-verification when using tools, resulting in long dialogue paths that can easily exceed the 128K limit. DeepSeek has tested several context management strategies (Summary, Discard-75%, Discard-all), which alleviate the problem but still have room for optimization.
How to Use
API Method:
The API calls for V3.2 are the same as the previous V3.2-Exp; just use it directly.
Speciale uses a temporary endpoint: https://api.deepseek.com/v3.2_speciale_expires_on_20251215, with the same price as V3.2, but it doesn't support tool calls and is only valid until December 15th. Primarily intended for researchers to evaluate.
V3.2 supports enabling thinking mode during tool calls. Note that if you're using frameworks like Terminus that simulate tool interaction via user messages, the thinking effect will be diminished because V3.2 clears the inference history with each user message. In this case, non-thinking mode is recommended.
Open Source Models:
Both versions are on HuggingFace:
V3.2 shows significant improvements in inference and agent capabilities, especially within the context of open-source models. However, it still lags behind top-tier closed-source models like Gemini 3.0 Pro.
DeepSeek also acknowledges several issues in its paper:
Suitable Scenarios
V3.2 is well-suited for these types of needs:
Projects requiring strong inference capabilities but not wanting to rely on closed-source APIs. V3.2 is approaching GPT-5 levels in mathematical, programming, and logical reasoning tasks, and it's completely open source.
For developers, the significance of V3.2 may go beyond just "another new model." In some tests, it has already matched GPT-5, and the Speciale version has even achieved gold medal-level results in math and programming competitions. More importantly, these capabilities are all open source.
Agent applications, especially code-related ones. Its SWE-bench performance proves its good bug-fixing ability in real-world code repositories. If you're developing tools for coding assistants, automated testing, or code review, V3.2 is a reliable choice.
Multi-step planning and complex tool invocation scenarios. While it doesn't quite match top-tier closed-source models on some benchmarks, V3.2 maintains inference capabilities during tool invocation, a first for open-source models.
If you're not sensitive to token consumption, or if the task itself requires deep inference (e.g., mathematical proofs, algorithm competitions, complex system design), Speciale would be a better choice.
What are the shortcomings?
DeepSeek also frankly mentions several limitations in its paper:
Its knowledge coverage is not as broad as top-tier closed-source models. This is due to fewer pre-training FLOPs, which can only be compensated for by increasing pre-training computation.
Token efficiency needs improvement. V3.2 typically requires longer inference chains to achieve the same quality, which translates to higher latency and cost in production environments.
There's still a gap in complex tasks. While it approaches GPT-5 in some tests, it falls short of top-tier models like Gemini 3.0 Pro in tasks requiring a combination of world knowledge and common-sense reasoning.
From my observation, the release of V3.2 represents another step forward for open-source models in the fields of inference and agents. Although it still lags behind top-tier closed-source models, it's sufficient for many practical applications. For developers looking to build AI applications using open-source solutions, this is a good option.
References
https://api-docs.deepseek.com/news/news251201
Leave your comment
- No comments yet.
Recommended AI Tools
Carefully selected AI tools to improve your work, study, and live efficiency.
Related Articles
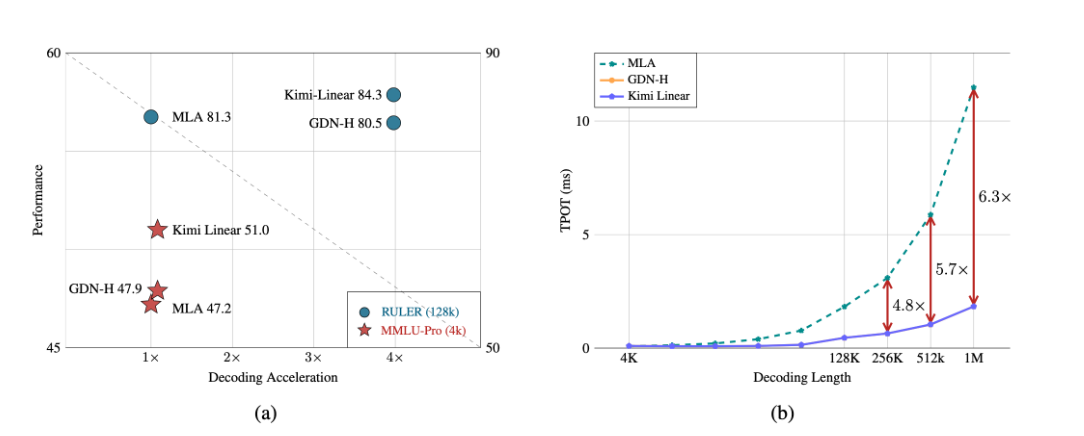
A major breakthrough has been achieved in the core architecture of large-scale models! The release of Kimi Linear marks the first time that linear attention technology has comprehensively surpassed and significantly outperformed the traditional Transformer full-attention model in both performance and efficiency. This "win-win" achievement is expected to significantly reduce the computational barriers and costs for long text processing, complex reasoning, and AI agent applications, potentially changing the competitive landscape of underlying technologies for large-scale models.

Over the past week, the AI community's attention has been drawn to a mysterious model that quietly emerged on the OpenRouter platform—Polaris Alpha. As a direct continuation of yesterday's discussion of the GPT-5.1 leak, this suddenly appearing model brings more technical details and strategic signals worthy of in-depth exploration.

A new paradigm in knowledge acquisition has arrived, this time powered by AI.

Standing at this moment in 2025, when we look back at the development journey of artificial intelligence, we witness how this revolutionary technology has reshaped every aspect of human society. From initial theoretical concepts to today's practical applications, each step forward in AI technology has changed the way we live. Let's revisit this fascinating journey together.