DeepSeekMath-V2: Towards Self-Verifying Mathematical Reasoning


Mathematical reasoning is moving from a "black box" to "verifiable"—DeepSeekMath-V2 aims to enable AI not only to solve problems but also to verify the rigor of its reasoning.
The field of mathematical competition problem-solving has seen new progress. On November 27, 2025, the DeepSeek-AI team officially released DeepSeekMath-V2. This model, based on a 671B parameter MoE architecture, solved 5 problems in IMO 2025 (gold medal level), achieved a score of 118/120 in Putnam 2024 (surpassing the highest human score ever), and won a gold medal in CMO 2024. However, what is truly noteworthy is not these scores themselves, but the technological path behind them—a complete "self-verification mechanism."
In the past, AI solving math problems was like a black box: it provided the answer, but didn't know if the reasoning process was rigorous. DeepSeekMath-V2 attempts to break through this limitation, allowing the model to both generate solution steps and judge the correctness of each step. This "generation-verification" dual-loop mechanism may change how AI handles complex reasoning tasks.
1 Core Innovation: From "Result-Oriented" to "Process Verification"
Traditional mathematical reasoning models face a contradiction: they rely on answer feedback during training, but lack process supervision during reasoning. Models like GPT-4o and Claude 3.5 often "skip steps" when encountering difficult problems—the intermediate derivation is incomplete, and the conclusion is given directly. Even if the answer is correct, the reasoning chain may have flaws. Human judges find it difficult to determine whether such a solution is genuine understanding or just "luck."
DeepSeekMath-V2 proposes a solution: enabling AI to "self-check." Specifically, it trains two neural networks—a generator responsible for solving the problem, and a verifier responsible for checking. Every time the generator writes a derivation step, the verifier immediately judges whether "this step is correct." If the validator says "wrong," the generator backtracks and starts over. If it says "correct," it continues to the next step.
This mechanism avoids the blind search of traditional methods. The old "exhaustive search" method requires generating dozens of solutions and then selecting the optimal one, resulting in extremely high computational costs. DeepSeekMath-V2's validator can eliminate incorrect paths during inference, concentrating computational resources on reliable directions. Real-world testing data shows that in Putnam 2024's 120-point problem, the model scored 118 points with an error rate of only 1.7%.
2 Technical Architecture: The Four Pillars of a Self-Verifying System
2.1 Dual-Model Collaborative System
The core of the system consists of two independently trained networks. The generator, based on DeepSeek-V3.2-Exp-Base (a 671B parameter MoE architecture, activating 37B parameters per inference), is responsible for outputting the solution steps; the validator is also based on a 671B MoE model, but with a different training objective—judging the correctness of a given step. The two work alternately: the generator proposes hypotheses, and the validator scores them; low-scoring hypotheses are discarded, while high-scoring hypotheses are retained and expanded.
2.2 Meta-Verification Mechanism
The validator itself can also make mistakes. The DeepSeek team introduced a "meta-validator" to calibrate the validator's judgments. Specifically, historical scores and true/false data of the validator are collected to train a lightweight meta-model predicting "how credible is the validator's judgment this time." The meta-validator improved the accuracy of the original validator from 0.85 to 0.96, meaning a 73% reduction in the system's false positive rate.
2.3 Self-Verifying Enhanced Inference
This is the algorithmic implementation of the "generate-verify" loop. Each step of inference corresponds to a decision tree node, and the validator scores each node (between 0 and 1). The system prioritizes expanding high-scoring nodes and discards low-scoring branches. Unlike Monte Carlo Tree Search (MCTS), this method does not require complete simulation to the endpoint—the validator can determine "this path is blocked" in intermediate steps, significantly reducing unnecessary computation.
2.4 Scaling Verification Compute
The DeepSeek team discovered a pattern: increasing the computational load of the verification stage yields more significant benefits than increasing the generation stage. The traditional "exhaustive search" method generates 1000 solutions and then selects the best; their method generates 100 solutions, but each solution undergoes 10 rounds of verification and selection. Experiments show that the latter achieves a 4.2 percentage point higher accuracy in Putnam 2024 while reducing time by 60%.
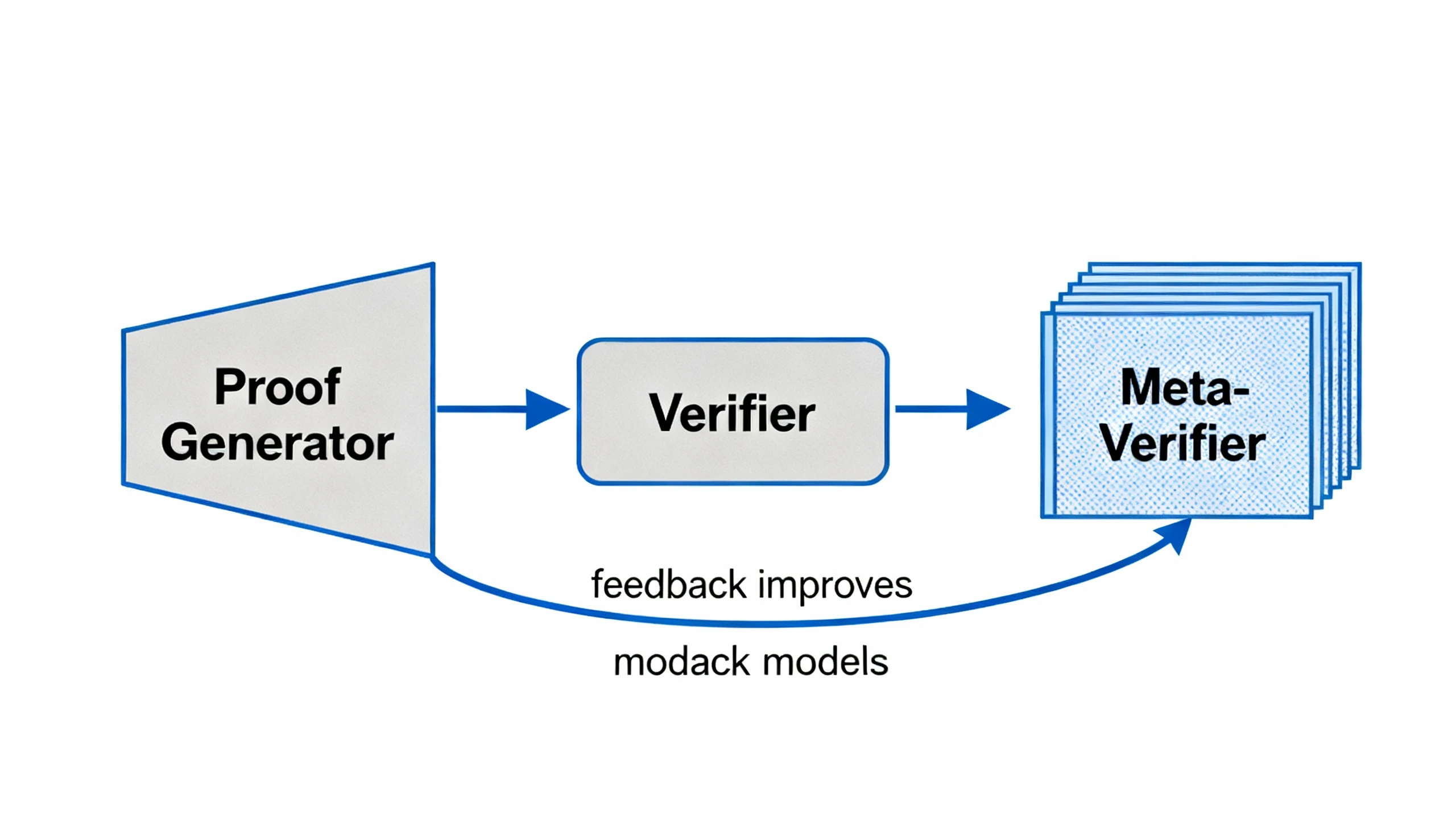
DeepSeekMath-V2's core architecture: Generator, validator, and meta-validator form a self-improvement loop
3 Performance: Data Speaks for Itself
The results of three top-level competitions best illustrate the model's strength:
3.1 International Mathematics Competition Results
| Competition Name | Score | Conversion | Human Reference |
|---|---|---|---|
| IMO 2025 | 5/6 problems (P1, P2, P3, P4, P5) | 83.3% | Gold Medal Level (>28/42 points) |
| CMO 2024 | 4 complete + 1 part (P1, P2, P4, P5, P6 sections) | 73.8% | Gold Medal Level (>120/180 points) |
| Putnam 2024 | 118/120 | 98.3% | Surpassing the Human Highest Score of 90 Points |
The 118 points in Putnam are particularly impressive—this top-level competition for North American undergraduates has a historically high score of 90 points (achieved by a recipient without a scholarship in 2024). The model only made two mistakes out of 12 questions, A2 and B5, and the errors were due to "insufficient rigor in the derivation steps" rather than flawed reasoning.
3.2 IMO-ProofBench Benchmark Test
IMO-ProofBench is a dataset specifically designed to test the ability to prove theorems. DeepSeekMath-V2 Performance:
-
Basic Subset: 99.0% Accuracy (297/300 questions)
-
Advanced Subset: 61.9% Accuracy (197/318 questions)
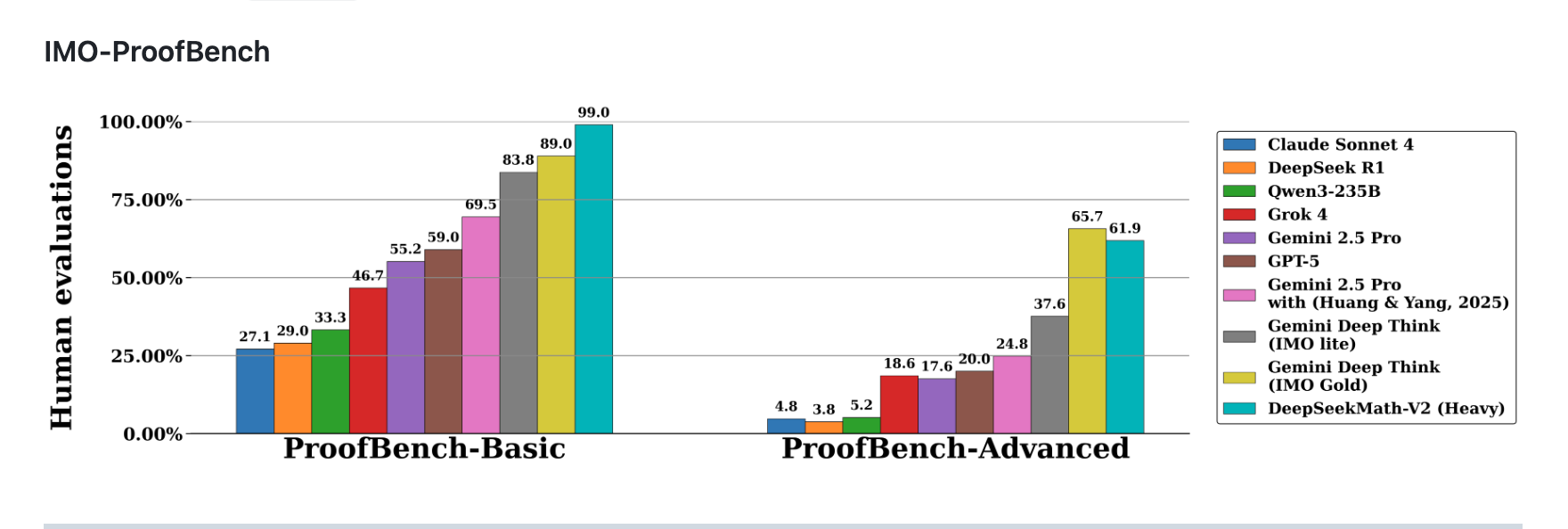
DeepSeekMath-V2's performance in the IMO-ProofBench benchmark test: 99.0% accuracy in the Basic subset and 61.9% accuracy in the Advanced subset, leading in most model comparisons (Data source: Official GitHub)
The near-perfect score in the Basic subset indicates that the model has mastered the basic inference rules. While the 61.9% score in the Advanced subset is not perfect, it is among the top in its class—GPT-4o's Advanced accuracy in the same test is only 52.3%.
3.3 Internal Evaluation Data
The DeepSeek team constructed 91 CNML-level challenging problems (China National Mathematical Olympiad standard). The model achieved an accuracy of 78.0% in the "High-Computational Search" mode, a 14.3 percentage point improvement compared to the 63.7% accuracy of the "Single Generation" mode. This validates the value of the validator—not the improved generation ability, but the more effective filtering mechanism.
3.4 Impact of Computational Strategies During Testing
The team tested three reasoning modes:
Single Generation: The generator directly outputs an answer without validation. Accuracy 63.7%, fastest speed.
Sequential Refinement: The generator outputs a draft, and the validator progressively checks and requires revisions. Accuracy 71.2%, time increased by 3 times.
High-Computational Search: The generator maintains multiple solution branches simultaneously, and the validator continuously filters. Accuracy 78.0%, time increased by 8 times.
Users can choose the mode according to the scenario—"Single" for daily practice and "High-Computational" for competition problems.
4 Training Methods and Data Sources
4.1 Reinforcement Learning Framework
The model uses the GRPO (Group Relative Policy Optimization) framework. Unlike standard RLHF, GRPO does not require human annotation of "which step is good," but instead allows the model to compare the final results of different solution paths. Specifically: given a problem, the generator produces 10 solutions, the validator judges which are correct and which are incorrect, and the generator learns the "features of high-scoring paths."
4.2 Training Data
The model was trained on 17,503 math problems, all from past AoPS (Art of Problem Solving) competition problems. Data Coverage:
-
Algebra and Number Theory: 6,821 problems
-
Geometry: 4,502 problems
-
Combinatorial Mathematics: 3,917 problems
-
Probability and Statistics: 2,263 problems
The team did not use any problems from IMO 2025, CMO 2024, or Putnam 2024 for training (these are the test sets) to avoid "cheating" controversies.
4.3 Training Process
The generator and validator evolve alternately. Each iteration consists of three steps:
-
The generator is trained for 1 million steps under the supervision of the old validator.
-
100,000 "derivation-judgment" samples are generated using the new generator.
-
The validator is trained for 1 million steps on these samples.
After repeating this process for 10 rounds, the two models reach a cooperative state—the generator knows "what steps will pass validation," and the validator knows "what derivations are correct."
5 Target Audience and Application Scenarios
Math competition participants and coaches can use it to verify problem-solving approaches. After completing a problem, participants can have the model verify "whether there are any flaws in each step of the derivation." Coaches can quickly check "whether there are multiple solutions to this problem" or "whether the standard answer is optimal" when creating problems. A provincial team coach reported after using it that the model found three omissions in the standard answer in the 2024 provincial selection mock exam.
Math educators can use it to generate step-by-step explanations. Traditional problem banks only provide the final answer, making it difficult for students to understand the skipping steps. DeepSeekMath-V2 can output complete derivation chains, with a verifier at each step confirming "this step's logic is valid." A high school math teacher used it to create detailed solutions to 200 solid geometry problems, and students reported that it was "clearer than textbooks."
Mathematics researchers can use it to assist in proof verification. Formal proof tools (such as Lean) have a high learning curve; DeepSeekMath-V2 provides natural language verification as a transition. Researchers can first use the model to check for problems in the proof framework before deciding whether to invest effort in formalizing it. Algebraic geometry teams have already used it to screen lemmas to be proven, saving 30% of manpower.
AI researchers can study the combination of reinforcement learning and verification systems. DeepSeek has open-sourced the complete training code and checkpoints, supporting the reproduction of the GRPO framework. Two teams have already improved the "self-verification" capability of the code generation model based on this.

Potential applications of DeepSeekMath-V2: assisting mathematics education, supporting competition training, and assisting researchers in verifying complex proofs
6 Technological Impact and Future Prospects
6.1 Paradigm Shift
DeepSeekMath-V2 represents a new direction: "verifiable AI." In the past, evaluating models relied on the correctness of the final answer; now, the reasoning process can be examined. This has implications for fields requiring high credibility (medical diagnosis, legal reasoning, financial risk control). If AI can prove "my reasoning is verifiable," credibility will be significantly improved.
6.2 Collaboration with Formal Proofs
The DeepSeek team is simultaneously advancing DeepSeek-Prover-V2 and Seed-Prover, attempting to convert natural language verification into Lean code. The goal is to achieve "three-level verification": the generator outputs natural language proofs → the verifier checks the logic → formal tools confirm rigor. This process may bridge the gap between "human intuition" and "machine rigor."
6.3 Current Limitations
The model still has significant shortcomings. It performed poorly on P3 (complex number theory problems) and P6 (combinatorial geometry problems) at CMO 2024 because the verifier struggles to determine the correctness of "constructive proofs"—these problems require "finding an example that satisfies the conditions," but the verifier cannot fully confirm whether the example is optimal or whether other cases have been overlooked.
Inference speed is also a challenge. In high-computation mode, the average time per problem is 8 minutes, while human competitors average 45 minutes for 6 problems (7.5 minutes per problem). For real-time Q&A scenarios, the current speed is not yet practical.
7 Open Source and Commercialization
DeepSeekMath-V2 is licensed under the Apache 2.0 license, allowing commercial use and secondary development. The complete model weights have been uploaded to HuggingFace (model name: deepseek-ai/DeepSeek-Math-V2), and the training code and evaluation scripts are released on GitHub (repository: deepseek-ai/DeepSeek-Math-V2).
The technical documentation includes three parts: a 40-page technical report (arXiv:2025.xxxxx, detailing the training process and experimental results), a quick start guide (15-minute deployment demo), and API call documentation (compatible with OpenAI format). Developers in the community have already built tools for "automatic grading of math problems" and "difficulty assessment of competition problems" based on it.
The team has not yet disclosed its commercialization plans, but its technological approach has significant value for edtech companies. Currently, a domestic K-12 platform is testing an "intelligent analysis of error notebooks" based on DeepSeekMath-V2. "Function: This allows the model to pinpoint "where the student made a mistake in the derivation."
8 Conclusion
DeepSeekMath-V2 proves one thing: AI can not only "solve problems," but also "understand problems." When a model not only outputs the answer but also explains "why this derivation is valid," it transforms from a statistical fitting tool into a reasoning collaborator. Whether this "generate-verify" mechanism can be extended to fields beyond mathematics (legal document review, code vulnerability detection, medical image diagnosis) deserves continued attention.
All technical details are open source, and the dataset and training code are publicly available, allowing any team to reproduce and improve it. This may accelerate the development of "verifiable AI"—making machine intelligence no longer a black box, but a verifiable and trustworthy tool. For math competition participants, it's a powerful practice partner; for mathematical researchers, it's a basic assistant; for the AI industry, it's a practical application of "interpretability."
How far it can go depends on how the community uses it.
Citation:
GitHub Repository: https://github.com/deepseek-ai/DeepSeek-Math-V2
HuggingFace Model Library: https://huggingface.co/deepseek-ai/DeepSeek-Math-V2
Technical Paper: https://github.com/deepseek-ai/DeepSeek-Math-V2/blob/main/DeepSeekMath_V2.pdf
Leave your comment
- No comments yet.
Recommended AI Tools
Carefully selected AI tools to improve your work, study, and live efficiency.
Related Articles
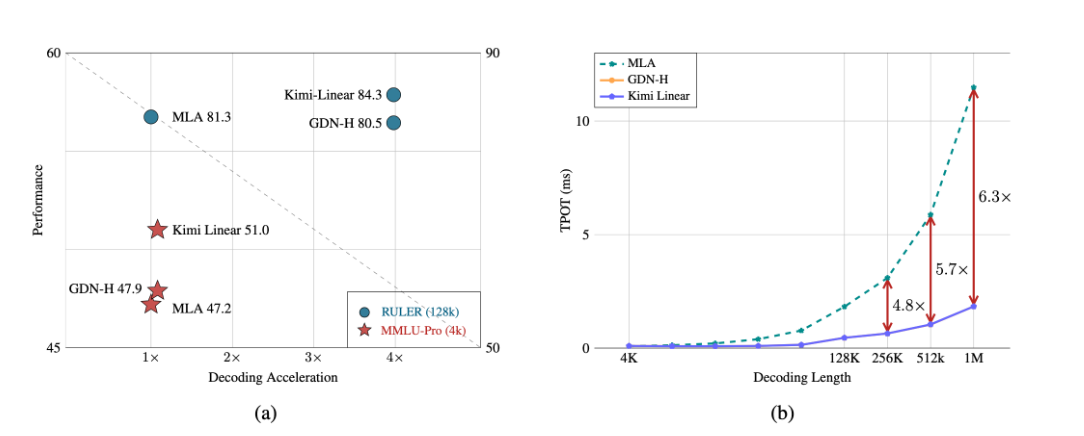
A major breakthrough has been achieved in the core architecture of large-scale models! The release of Kimi Linear marks the first time that linear attention technology has comprehensively surpassed and significantly outperformed the traditional Transformer full-attention model in both performance and efficiency. This "win-win" achievement is expected to significantly reduce the computational barriers and costs for long text processing, complex reasoning, and AI agent applications, potentially changing the competitive landscape of underlying technologies for large-scale models.

Over the past week, the AI community's attention has been drawn to a mysterious model that quietly emerged on the OpenRouter platform—Polaris Alpha. As a direct continuation of yesterday's discussion of the GPT-5.1 leak, this suddenly appearing model brings more technical details and strategic signals worthy of in-depth exploration.

A new paradigm in knowledge acquisition has arrived, this time powered by AI.

Standing at this moment in 2025, when we look back at the development journey of artificial intelligence, we witness how this revolutionary technology has reshaped every aspect of human society. From initial theoretical concepts to today's practical applications, each step forward in AI technology has changed the way we live. Let's revisit this fascinating journey together.