Gemini 3 DeepThink In-Depth Review: Another Breakthrough in AI Reasoning Capabilities

This was an unexpected yet perfectly logical surprise.
width="100%"
height="450"
frameborder="0"
allow="accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture"
allowfullscreen>
Frankly, over the past year, we've become accustomed to seeing various large models "chasing" each other on the benchmark charts, often with only a few tenths of a percentage point difference. But this DeepThink release felt completely different. It wasn't simply adding to existing features; it was attempting to reconstruct the way models "think."
More Than Just "Slow Thinking"
If previous Chain-of-Thought models taught the model to "think step by step," then Gemini 3 DeepThink brings Parallel Reasoning.
This is a crucial difference. When using previous reasoning models (such as the early O1 series), we often felt they were performing linear, deep-digging analysis. The model was like a student stubbornly sticking to a single logical path. This approach is effective for solving certain problems, but if the initial direction is wrong, it will stray further and further down the wrong path, eventually leading to illusions or logical collapse.
Google's "parallel reasoning" technology gives the model the ability to "split itself." When faced with a complex mathematical problem or logical trap, DeepThink no longer gambles everything but simultaneously constructs multiple hypothetical paths. You can imagine it as a Go master simultaneously considering a dozen possibilities for the next five moves. It assesses the feasibility of each path, quickly discarding seemingly hopeless dead ends, and then concentrates computing power on the most promising path for further exploration.
The direct result of this mechanism is its extremely high "error correction rate." In my initial tests, DeepThink rarely falls directly into logic problems with deliberately set premise traps, because during parallel thinking, it's highly likely that one path has already discovered the premise fallacy.
The Truth Behind the Data: When GPT-5 Meets a Formidable Rival
Talking about technical principles alone is somewhat abstract; let's look at the solid benchmark data. Google's benchmark results this time are very hardcore, especially compared to top contenders like Claude Sonnet 4.5, GPT-5 Pro, and even GPT-5.1.
The following image shows three highly representative benchmark comparisons with a wealth of data; I recommend you take a close look:
Detailed Evaluation Data Comparison
Google's official evaluation data covers three key dimensions: reasoning and knowledge, scientific knowledge, and visual reasoning ability. Below is the complete data comparison:
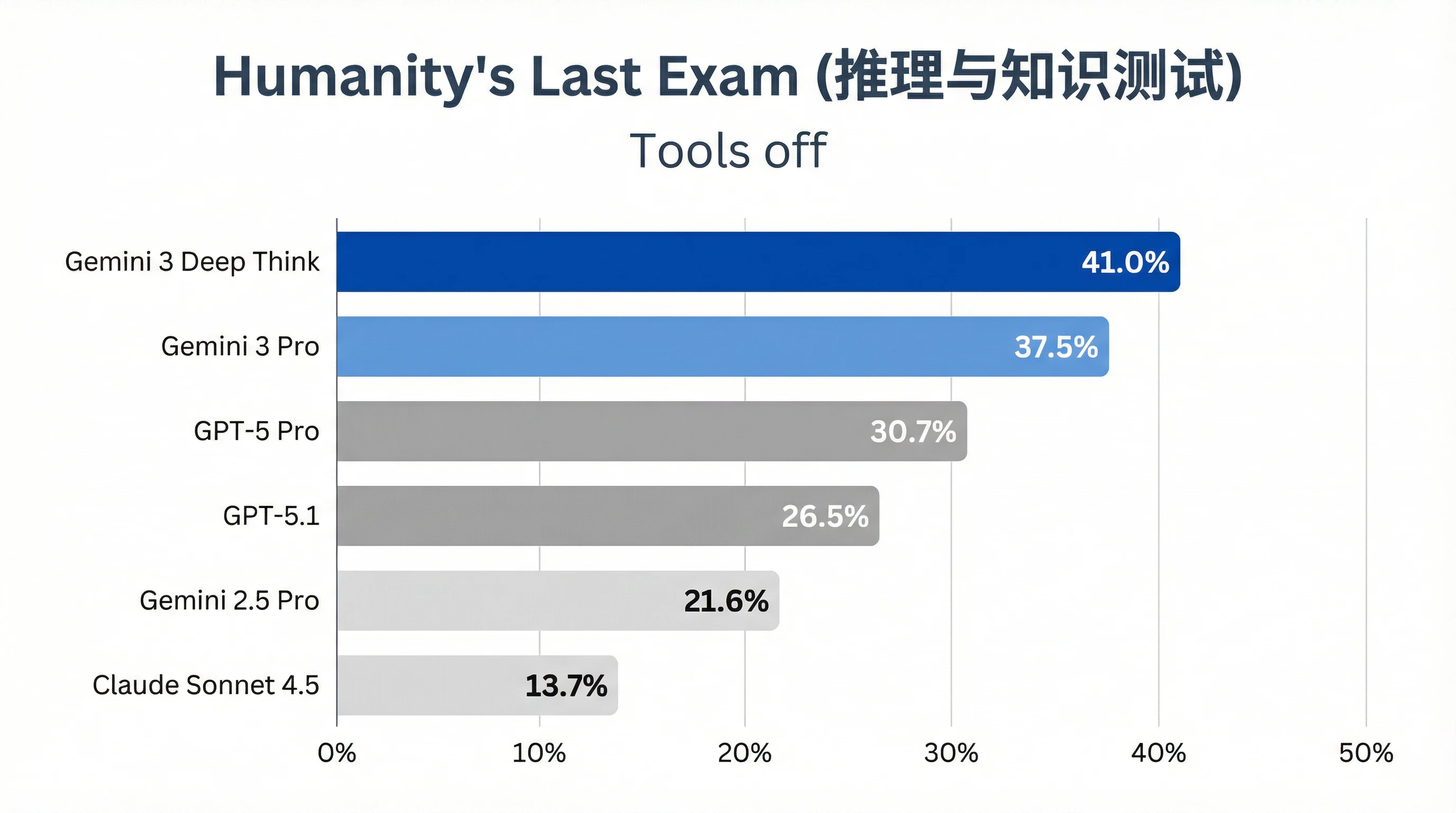
1. Humanity's Last Exam (Reasoning and Knowledge Test)
Test Conditions: Tools off (No external tools used)
This test, known as "Humanity's Last Exam," aims to evaluate a model's autonomous reasoning ability on open-ended questions. DeepThink leads with a score of 41%, 3.5 percentage points higher than the second-place Gemini 3 Pro and a full 10.3 percentage points higher than the GPT-5 Pro.
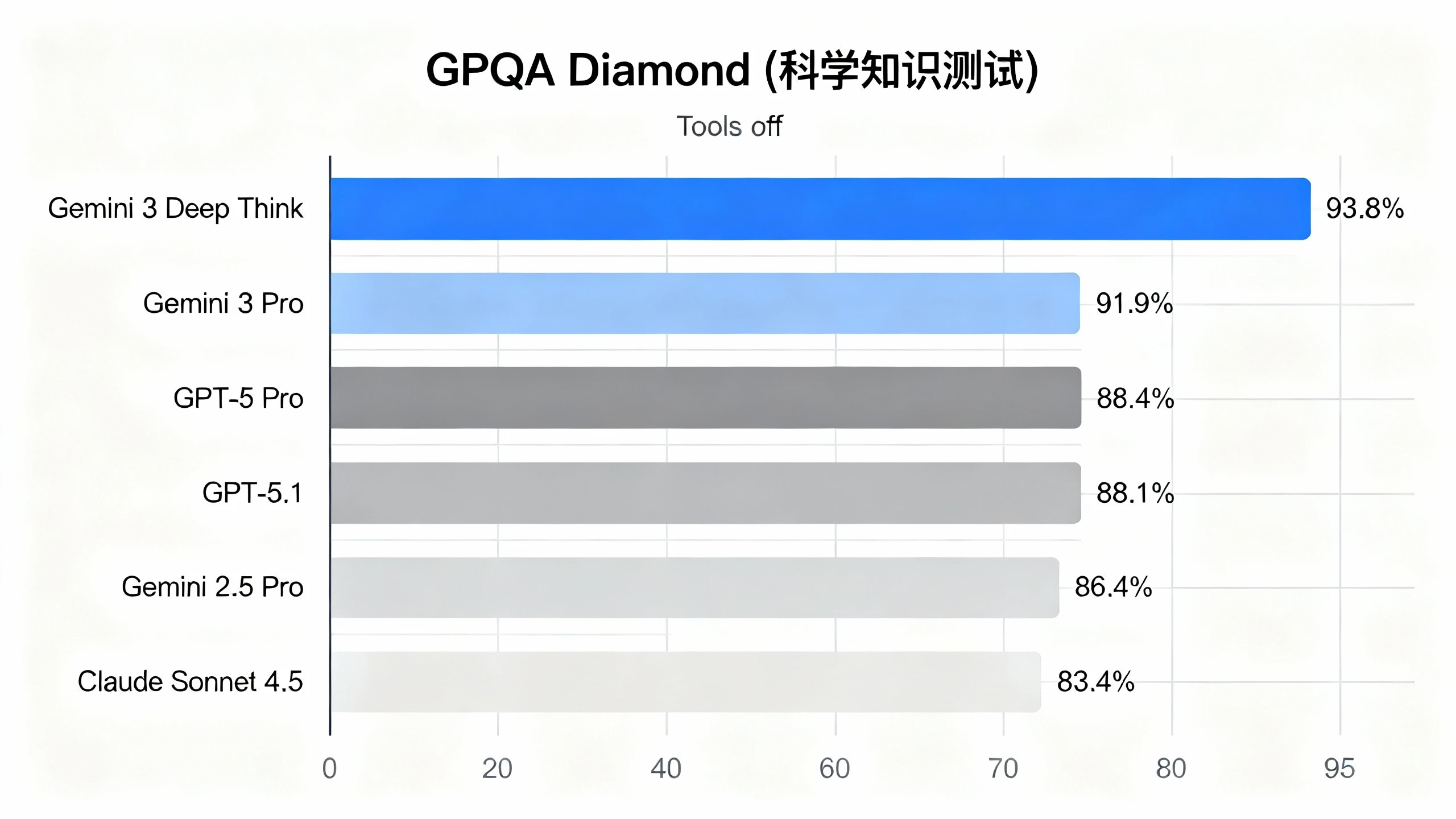
2. GPQA Diamond (Science Knowledge Test)
Testing Conditions: Tools off (No external tools used)
GPQA Diamond is a graduate-level science knowledge test covering multiple disciplines such as physics, chemistry, and biology. DeepThink tops the list with an accuracy rate of 93.8%. In this high score range, every 1% improvement significantly reduces professional-level illusions.
3. ARC-AGI-2 (Visual Reasoning Puzzle)
Test Conditions: Tools on (Code execution allowed)
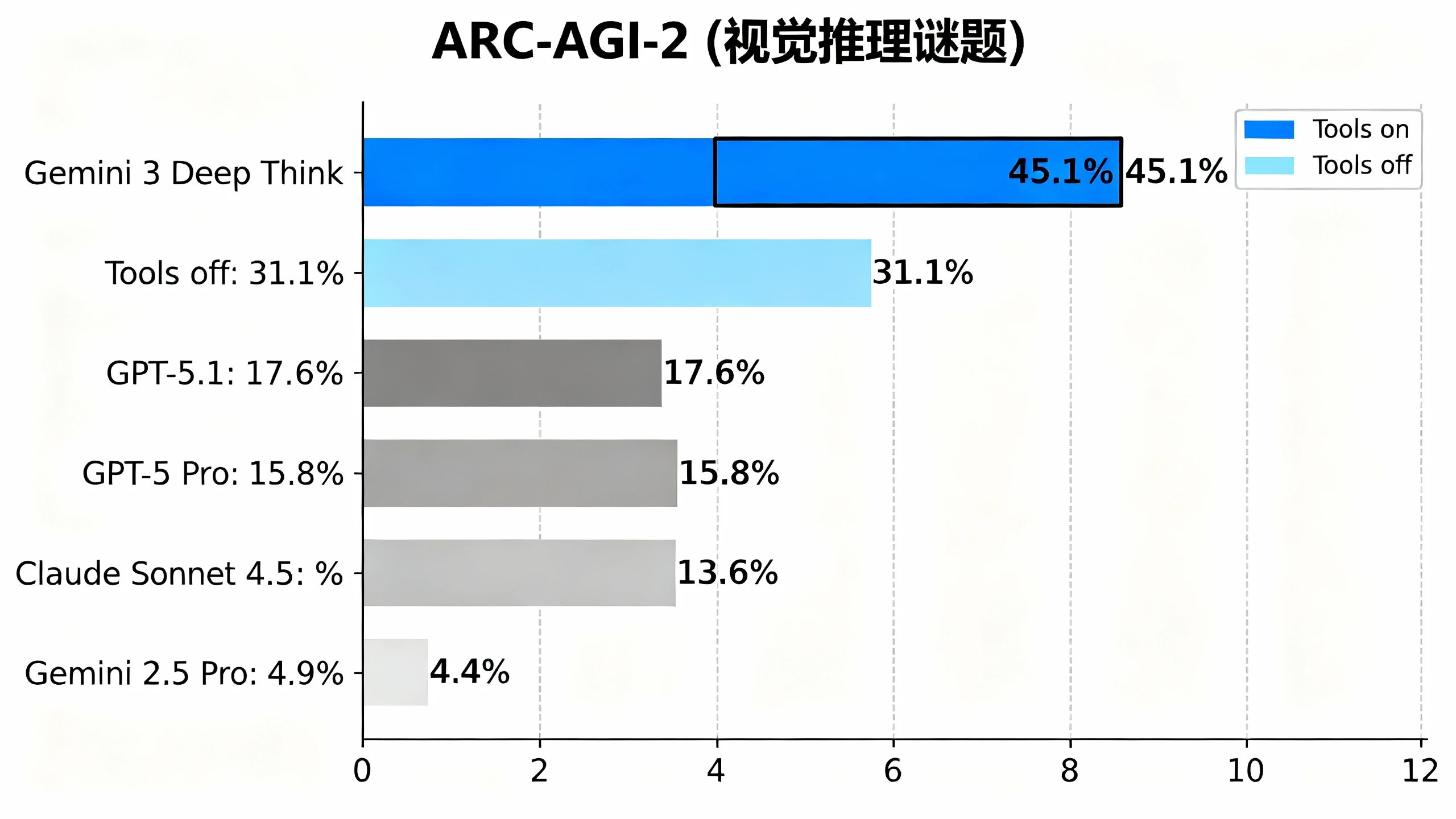
ARC-AGI-2 is considered the closest benchmark to testing "general fluid intelligence," requiring models to understand abstract visual patterns never seen before. DeepThink's 45.1% score is a milestone breakthrough, almost 2.5 times that of GPT-5.1 (17.6%), and an astonishing 820% improvement over its predecessor, Gemini 2.5 Pro (4.9%). The image below is an official comparison chart, clearly showing the performance of the three tests:
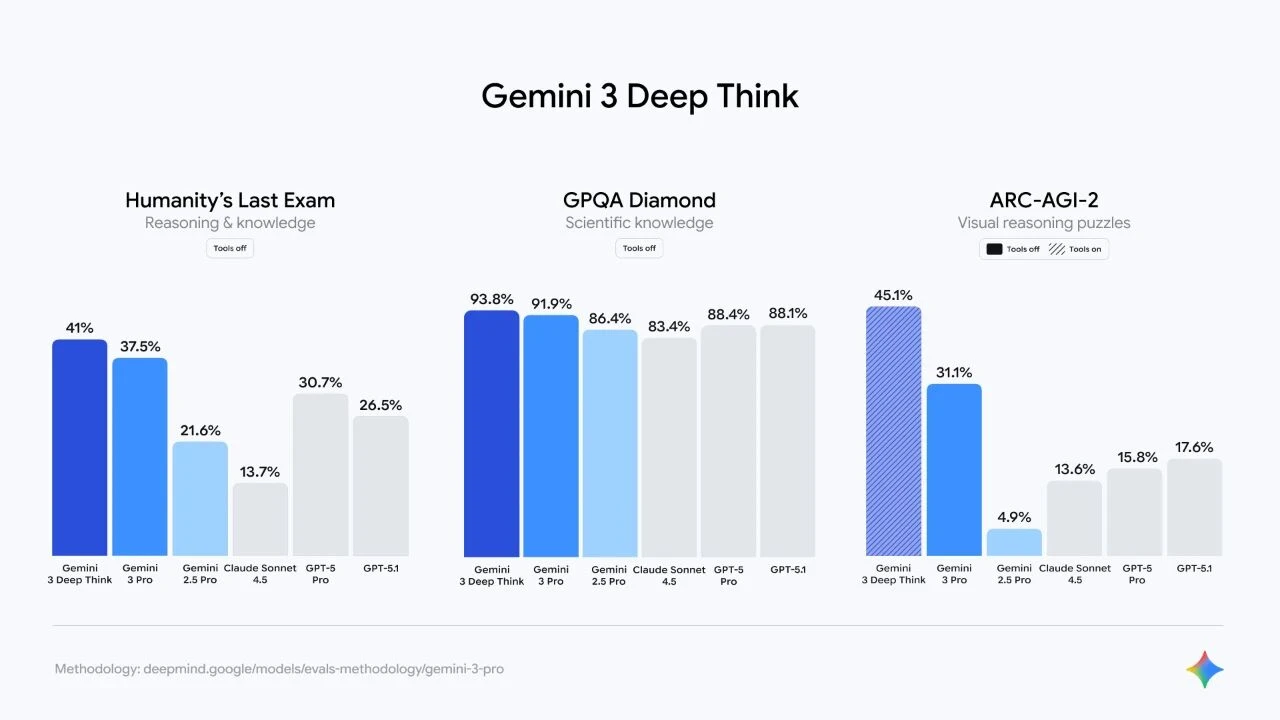
Let's focus on some of the most disruptive data points.
First is ARC-AGI-2. This isn't just a score; it's a watershed moment.
Those familiar with AI evaluations know that ARC (Abstraction and Reasoning Corpus) has always been a nightmare for LLM (Liquidity Logic). It doesn't test rote memorization; it tests pure visual logic and immediate learning ability—what's commonly known as "general fluid intelligence." For a long time, even the strongest models only managed single-digit or barely above-average scores on this list.
Looking at the data in the image, Gemini 2.5 Pro only scores 4.9%, which is essentially "completely incomprehensible." Claude Sonnet 4.5 and GPT-5 Pro improved to the 13-15% range; while there was progress, it still felt like they "got some right."
However, Gemini 3 DeepThink directly boosted this number to 45.1% (Tools on, meaning it allows code-assisted learning). Even without tools, it achieved 31.1%, almost double the performance of GPT-5.1. This means the model is no longer just making text predictions; it truly understands abstract patterns and can translate this understanding into code to verify its conjectures. This leap in capability is mainly attributed to "parallel reasoning"—trying multiple possible transformation rules when faced with an unfamiliar puzzle until the correct solution is found.
Now let's look at Humanity's Last Exam. While the name might sound a bit dramatic, it's widely recognized as one of the most challenging integrated reasoning tests, designed to test a model's autonomous exploration capabilities without specific instructions.
DeepThink achieved 41.0% here. In comparison, Claude Sonnet 4.5 only reached 13.7%, and even the currently powerful GPT-5 Pro only reached 30.7%. This 10 percentage point difference is terrifying in high-level games. This demonstrates that when problems become extremely complex, requiring interdisciplinary knowledge and multi-step logical leaps, DeepThink's "multi-path thinking" mode exhibits overwhelming stability.
As for GPQA Diamond (scientific knowledge), although the gap between the two isn't as large (DeepThink 93.8% vs GPT-5 Pro 88.4%), this represents a significant improvement. In the range above 90 points, each point increase means reducing a large amount of professional-level illusion. For users who need AI-assisted scientific research, this 5% accuracy improvement could be the difference between "experimental success" and "three days of error checking."
From Math Olympiad Gold Medals to Everyday Productivity
If it were just about chart-topping performance, DeepThink wouldn't excite me so much. What truly makes me feel its "future is promising" is its underlying technological foundation.
The official blog (https://blog.google/products/gemini/gemini-3-deep-think/) reveals that the Gemini 3 DeepThink's technological base is actually evolved from the Gemini 2.5 variant, which achieved gold medal status in the International Mathematical Olympiad (IMO) and the International Collegiate Programming Contest (ICPC).
What does this mean? It means that this system was originally designed for "solving difficult problems," not for "chatting."
How will this capability translate into real-world applications?
If you are a programmer, when you throw a piece of code full of subtle bugs at DeepThink, it won't give you a vague fix suggestion like a typical model. It might construct three different debugging approaches in parallel in the background (i.e., during its thought process):
-
Suspect a memory leak;
-
Suspect a race condition;
-
Suspect a third-party library version incompatibility.
It will attempt to verify these three hypotheses and finally tell you: "Although it looks like a memory issue, after verification, this is actually a rare concurrent deadlock, and we recommend modifying it this way..." This is the dimensionality-reducing advantage of parallel reasoning on the engineering side.
For researchers, when conducting literature reviews or generating hypotheses, DeepThink can simultaneously interpret the same set of experimental data from different theoretical frameworks, providing more multi-dimensional perspectives, rather than just offering the most common explanation.
The Cost and Future of Thinking
Of course, DeepThink isn't without its barriers. As a feature only available to Ultra subscribers, its inference costs are clearly high. In actual use, the response speed is indeed slower in "Deep Think" mode compared to normal mode. The flashing thinking status icon on the screen constantly reminds you that a significant amount of computing power is being consumed in the background.
But this wait is worthwhile. We are witnessing a full evolution of AI from "System 1" (fast thinking, intuitive reaction) to "System 2" (slow thinking, logical reasoning).
The emergence of the Gemini 3 DeepThink, to some extent, breaks the monopoly of the GPT series in the high-end inference field. The 45.1% ARC score is a signal, telling us that on the road to AGI, besides accumulating computing power and data, innovation in algorithmic architecture—such as this parallel inference mechanism that mimics human "deliberate thinking"—still has enormous potential for development.
For the average AI user, the choices have become more interesting: if you simply need to write an email or polish an article, a standard Pro model is more than sufficient; but if you've encountered a truly challenging problem and need an assistant that can work alongside you, even thinking more comprehensively than you, the Gemini 3 DeepThink is undoubtedly one of the most worthwhile tools to try.
References
Leave your comment
- No comments yet.
Recommended AI Tools
Carefully selected AI tools to improve your work, study, and live efficiency.
Related Articles
A major breakthrough has been achieved in the core architecture of large-scale models! The release of Kimi Linear marks the first time that linear attention technology has comprehensively surpassed and significantly outperformed the traditional Transformer full-attention model in both performance and efficiency. This "win-win" achievement is expected to significantly reduce the computational barriers and costs for long text processing, complex reasoning, and AI agent applications, potentially changing the competitive landscape of underlying technologies for large-scale models.

Over the past week, the AI community's attention has been drawn to a mysterious model that quietly emerged on the OpenRouter platform—Polaris Alpha. As a direct continuation of yesterday's discussion of the GPT-5.1 leak, this suddenly appearing model brings more technical details and strategic signals worthy of in-depth exploration.

A new paradigm in knowledge acquisition has arrived, this time powered by AI.

Standing at this moment in 2025, when we look back at the development journey of artificial intelligence, we witness how this revolutionary technology has reshaped every aspect of human society. From initial theoretical concepts to today's practical applications, each step forward in AI technology has changed the way we live. Let's revisit this fascinating journey together.