In-depth analysis of Gemini 3 Flash: The terminator of inference costs

As someone who has long followed the AI tool ecosystem, I've witnessed countless manufacturers' "ranking-up" parameter races. However, the emergence of Gemini 3 Flash solves a long-standing pain point in the industry: how to reduce cost and latency to a production-ready level without sacrificing inference capabilities.
Next, I will delve into the Gemini 3 Flash from four dimensions: technical parameters, cost-effectiveness, inference mechanism, and practical applications.
I. Repositioning: The "Impossible Triangle" of Speed and Intelligence
In the past, choosing a "Flash" model usually meant compromise: you gained extremely fast speed and a low price, but had to endure weaker logical inference capabilities. Gemini 3 Flash is breaking this stereotype.
According to official reports, Gemini 3 Flash's positioning is very precise—it's a balanced product that combines the Pro-level inference capabilities of the previous generation with the response speed of Flash.
-
Speed Dimension: Compared to the Gemini 1.5 Flash, its latency is further reduced; and compared to the comparable Gemini 2.5 Pro, its response speed is a full 3x faster.
-
Cost Dimension: This is the most surprising part. Its inference cost is only 1/10 of the Gemini 2.5 Pro.
-
Capability Dimension: In benchmark tests, it did not sacrifice intelligence for speed; its core inference capabilities maintained remarkable consistency with Pro-level models.
For developers building Agent workflows or real-time interactive applications, this means you no longer need to make the difficult choice between "smart but slow" and "fast but clumsy".
II. Core Technology Breakthrough: Modular "Thinking" Capability
The most noteworthy technical feature of the Gemini 3 Flash is the introduction of a "thinking" process similar to the OpenAI o1 series, but Google has gone further—they have given developers control.
1. Dynamic Thinking Tokens
Unlike traditional "black box" reasoning, Gemini 3 Flash allows the model to generate "thinking tokens" before outputting the final answer. These tokens represent the model's chain of thoughts, used to handle complex logical problems.
-
Adaptive Complexity: The model dynamically adjusts the depth of its thinking based on the difficulty of the task. Simple questions and answers are output directly, while complex code refactoring or mathematical proofs consume more thinking tokens.
-
User-Controllable: Developers can set a budget cap for thinking tokens via API. This provides significant flexibility—limiting the length of thinking to save costs when handling non-critical tasks, and relaxing the limits to ensure accuracy when handling core logic.
2. Native Multimodal Integration
Google continues to leverage its traditional strengths in the multimodal domain. Gemini 3 Flash is more than just a text model; it demonstrates high efficiency in visual understanding and video analytics. Especially its ability to extract key information from the context of long videos, coupled with its extremely low token price, makes the automated processing of video content truly economically feasible.
III. Performance Benchmarking: The Truth Behind the Data
To objectively evaluate the capabilities of the Gemini 3 Flash, we integrated data from key benchmark tests such as GPQA, MMMU, and SWE-bench.
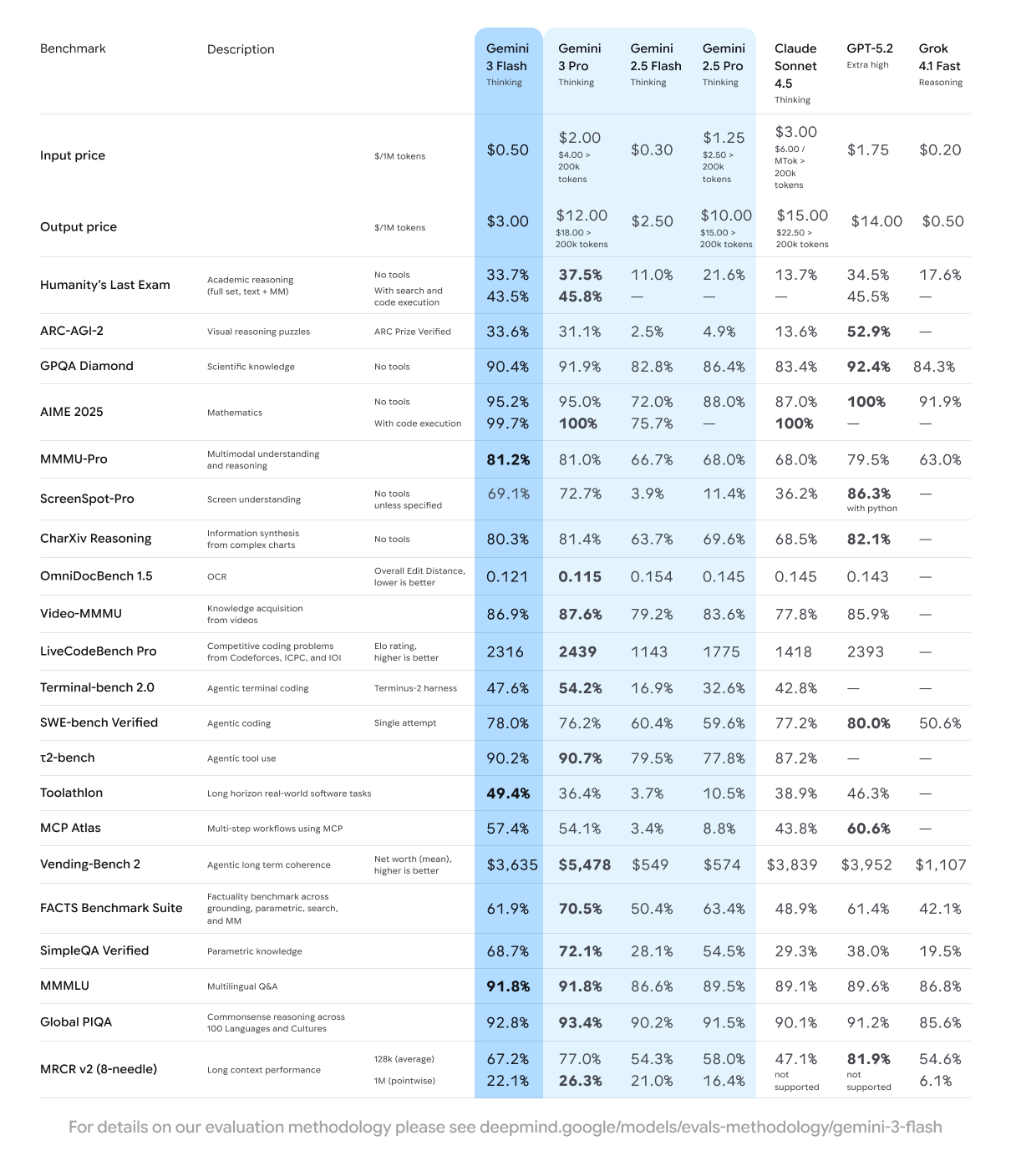
Key Highlights from the Table: Official benchmark data shows that Gemini 3 Flash achieved a high score of 90.4% in the GPQA Diamond (Doctoral-level Scientific Question Answering) test. This score not only far surpasses the previous generation Flash model but also approaches that of many manufacturers' high-end models. A score of 81.2% in MMMU Pro (Multimodal Understanding) demonstrates its versatility, while a performance of 78% in SWE-bench (Software Engineering) indicates its full capability for code review and generation tasks. Most importantly, it achieved these results at only 1/10th the cost.
Key Findings:
-
Pareto Frontier of Cost-Effectiveness: In the "cost-performance" framework, Gemini 3 Flash is currently at the best level in the market. It achieves near-industry-leading performance with extremely low resource consumption.
-
Developer Concerns: For programming and logical reasoning tasks, Gemini 3 Flash significantly outperforms similarly priced Claude 3 Haiku or GPT-4o mini, and in some scenarios, it can even replace the expensive GPT-4o or Claude 3.5 Sonnet.
IV. Cost-Benefit Analysis: A Developer's Calculation
Pricing strategies often determine the breadth of technology adoption. Google's pricing this time is extremely aggressive:
-
Input: $0.50 / 1M tokens
-
Output: $3.00 / 1M tokens (Output costs are typically lower if Thinking functionality isn't used)
What does this mean?
Imagine you're developing a RAG (Retrieval Augmentation Generative) application that requires reading a large amount of documents. Using Gemini 3 Flash, you can read 2 million words (approximately 2M tokens) of contextual data for only $1.
For Agent developers, agents often require multiple rounds of self-reflection and tool calls. Previously, this model was difficult to commercialize due to the enormous token consumption; now, Gemini 3 Flash lowers this barrier by an order of magnitude.
V. Recommended Application Scenarios
Based on the above analysis, I recommend the following types of users focus on Gemini 3 Flash:
-
Developers with high-frequency iterations: In scenarios such as code writing, unit test generation, and log analysis, Gemini 3 Flash's 78% SWE-bench score, combined with low latency, provides an extremely smooth IDE experience.
-
Agent system builders: Complex agent workflows require numerous intermediate inference steps. Using controllable thinking tokens, you can maintain agent intelligence while strictly controlling the cost of each interaction round.
-
Enterprise-level data processing: Through Vertex AI integration, enterprises can process massive amounts of unstructured data (contracts, financial reports, video conference recordings) without worrying about budget overruns.
-
Real-time interactive applications: For latency-sensitive scenarios such as customer service robots and voice assistants, Gemini 3 Flash is currently the best choice.
VI. Access and Ecosystem
Google has made Gemini 3 Flash accessible across all channels:
-
Developers: Direct access via Google AI Studio and Gemini API.
-
Enterprise Users: Vertex AI is also available, supporting enterprise-level security and compliance deployment.
-
Regular Users: The Gemini App (web and mobile versions) has switched to Gemini 3 Flash as the default model, allowing users to experience its speed improvements for free.
-
Cutting-Edge Exploration: Through the Google Antigravity program, some developers can try out more radical features early.
VII. Conclusion: A Victory for Pragmatists
Gemini 3 Flash is not just a "toy" model for writing poetry or drawing graphics; it's a Swiss Army knife that Google has handed to the engineering community.
While we may still need the Gemini 3 Pro or even the future Ultra version for research tasks pushing the limits of human cognition, the Gemini 3 Flash offers the best solution currently available for 95% of practical applications—from code completion to document summarization, from data cleaning to simple logical reasoning.
A one-sentence recommendation: If your project is still using the previous generation Flash model, or if you're still tolerating the intellectual limitations of the 7B small model due to cost constraints, now is the time to migrate to the Gemini 3 Flash. This is not just an upgrade, but a restructuring of the product's cost structure.
Reference: https://blog.google/products/gemini/gemini-3-flash/
Leave your comment
- No comments yet.
Recommended AI Tools
Carefully selected AI tools to improve your work, study, and live efficiency.
Related Articles
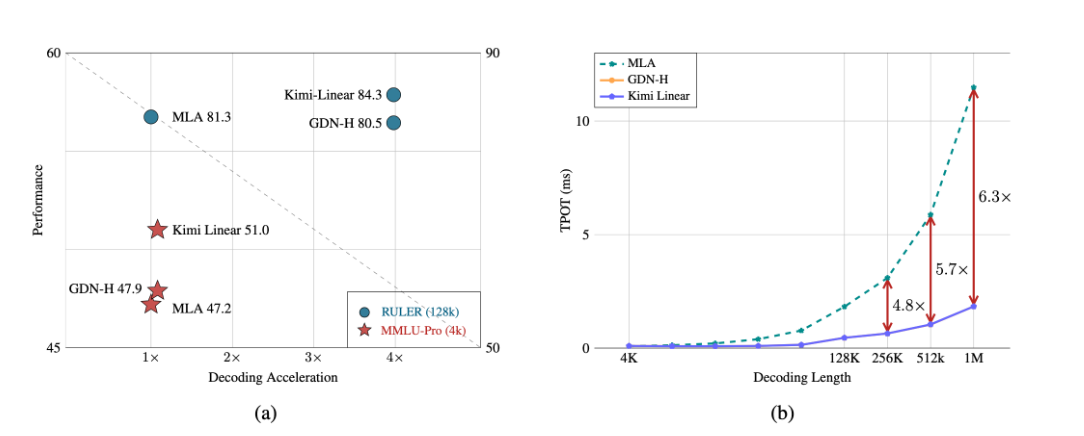
A major breakthrough has been achieved in the core architecture of large-scale models! The release of Kimi Linear marks the first time that linear attention technology has comprehensively surpassed and significantly outperformed the traditional Transformer full-attention model in both performance and efficiency. This "win-win" achievement is expected to significantly reduce the computational barriers and costs for long text processing, complex reasoning, and AI agent applications, potentially changing the competitive landscape of underlying technologies for large-scale models.

Over the past week, the AI community's attention has been drawn to a mysterious model that quietly emerged on the OpenRouter platform—Polaris Alpha. As a direct continuation of yesterday's discussion of the GPT-5.1 leak, this suddenly appearing model brings more technical details and strategic signals worthy of in-depth exploration.

A new paradigm in knowledge acquisition has arrived, this time powered by AI.

Standing at this moment in 2025, when we look back at the development journey of artificial intelligence, we witness how this revolutionary technology has reshaped every aspect of human society. From initial theoretical concepts to today's practical applications, each step forward in AI technology has changed the way we live. Let's revisit this fascinating journey together.