Google Gemini 3: The Most Powerful AI Model Arrives

What does this mean for developers and users? It means an all-rounder capable of handling text, images, video, audio, and code simultaneously; a super brain with millions of context windows, capable of reading an entire book in one go; an AI assistant that no longer just answers questions but proactively plans and executes complex tasks.
The timing of Gemini 3's release is intriguing. Just as OpenAI's GPT series and Anthropic's Claude were locked in fierce competition, Google announced its return with a set of astonishing benchmark data. This AI arms race has reached a new turning point.

Figure 1: Google Gemini 3.0 Pro, AI Evolution from Passive Tool to Active Agent
I. Three Major Technological Breakthroughs: More Than Just Parameter Upgrades
1. Million-Level Context: A Leap in Memory Capacity
One of the most striking features of Gemini 3.0 Pro is its support for ultra-long context windows of up to 1 million tokens. This isn't just a simple numbers game—it means the model can process approximately 900 files (each with up to 900 pages), 45 minutes of video content, or even 8.4 hours of audio simultaneously in a single conversation.
What does this mean for developers? You can dump an entire codebase on it for analysis, allowing it to understand the project's overall logic before writing code. For researchers and writers, you can upload dozens of academic papers for it to extract key points, or simply throw in a book for it to generate reading notes. More importantly, this capability doesn't require a separate encoder—Gemini 3 natively supports multimodal input, understanding text, images, videos, audio, and code within the same context. This design significantly reduces information loss and makes cross-modal reasoning much smoother.
2. Multimodal Understanding: Truly Seeing the World
If the previous generation of AI models was visually impaired, then Gemini 3 possesses a true visual system. It can:
-
Real-time Video Analysis: Supports 60 FPS video input, not just simple frame-by-frame analysis, but understanding continuous actions and time sequences.
-
Understanding 3D Space: Able to recognize spatial relationships between objects and geospatial data.
-
Recognizing Handwritten Content: In official demonstrations, Gemini 3 accurately recognized notes mixed with handwritten symbols and eliminated ambiguity.
What do these capabilities mean in practical applications? In education, it can understand students' handwritten problem-solving processes and provide feedback. In the medical field, it can analyze medical images and correlate them with medical records. In industrial settings, it can monitor production line videos and detect anomalies in real time.
3. Agent Capabilities: From "Answering Questions" to "Solving Problems"
The biggest highlight of Gemini 3 may not be that it's "smarter" than its predecessor, but rather that it's more "proactive." Through the new Google Antigravity platform, developers can build AI agents that work across editors, terminals, and browsers.
Specifically, the interaction mode of traditional AI models is "you ask, I answer," while Gemini 3 can:
-
Autonomous Task Planning: You say, "Plan a trip to Tokyo for me," and it will automatically find flights, hotels, attractions, and generate a complete itinerary with a schedule, budget, and transportation suggestions.
-
Multi-Step Execution: In the demonstration, Gemini 3 successfully and automatically organized its Gmail inbox, extracting key information and categorizing it for archiving.
-
Full-Process Code Collaboration: From understanding requirements to writing, testing, and debugging code, it can quickly build React applications and even generate web games within Google AI Studio.
Google claims that Gemini 3's coding capabilities are improved by more than 20% compared to Gemini 2.5 Pro. In the SWE-bench Verified test, which measures real-world software engineering problem-solving capabilities, the Gemini 3 Pro scored 76.2%, achieving industry-leading performance.
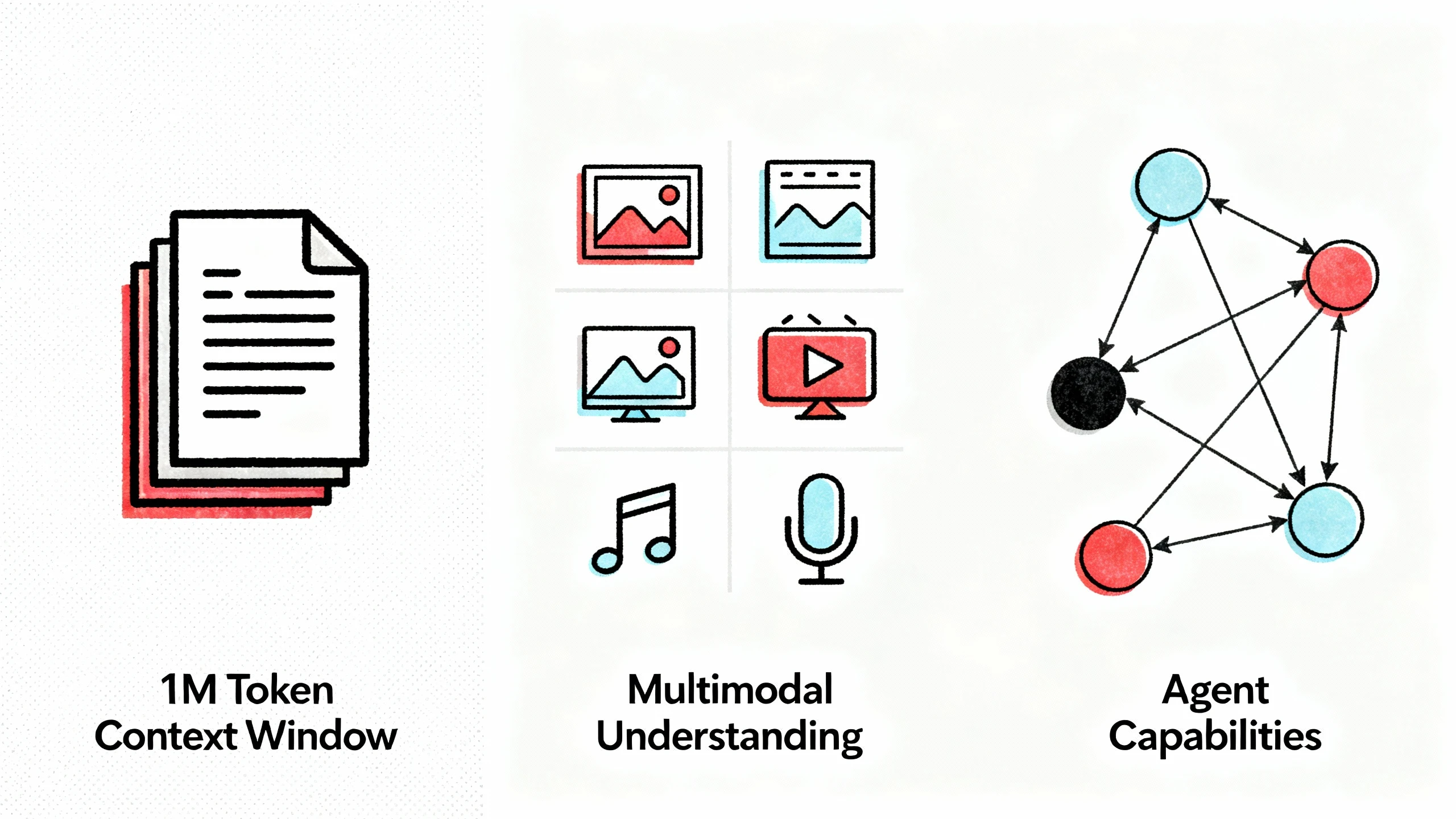
Figure 2: Gemini 3's Three Major Technological Breakthroughs—Million-Level Context, Native Multimodal Understanding, and Agent Capabilities
II. Performance Testing: Data Doesn't Lie
In the world of AI models, official marketing is always full of superlatives, but what truly convinces people is benchmark data. How did the Gemini 3 perform this time? ### Core Metrics Comparison

Figure 3: Performance Comparison of Gemini 3 with Mainstream AI Models—Leading Performance in Multiple Authoritative Tests
Overall Ranking
- LMArena Leaderboard: Gemini 3.0 Pro tops the global rankings with a score of 1501 Elo, surpassing all competitors
General Knowledge and Reasoning
-
MMLU (Multi-Domain Knowledge Understanding): Gemini 3.0 Pro 91.8% vs GPT-5.1 91.0%
-
GPQA Diamond (Graduate Level Reasoning): Gemini 3.0 Pro 91.9% vs GPT-5.1 88.1%
Mathematical Reasoning
- MathArena Apex: Gemini 3.0 Pro Score 23.4%, Setting a New Industry Standard
Code Capabilities
-
HumanEval (Python Programming): Gemini 3 74.4% vs GPT-4 67%
-
SWE-bench Verified (Software Engineering): Gemini 3.0 Pro 76.2% vs Claude 4.5 77.2%
Special Capability: Deep Think Mode
Gemini 3 also introduces an enhanced inference mode called "Deep Think." In this mode, the model engages in deeper thinking and logical planning, similar to the "slow thinking" humans use when solving complex problems.
In the highly challenging "Humanity's Last Exam" test:
-
Gemini 3 Deep Think: 41.0%
-
Gemini 3.0 Pro (Standard Mode): 37.5%
This feature will be available to AI Ultra subscribers in the coming weeks for tasks requiring complex inference.
How to interpret these data?
It's important to note that different benchmark tests have different focuses, and AI models are updated and iterated very frequently. Looking at the data:
-
General Knowledge and Reasoning: Gemini 3 leads across the board, showing a clear advantage in highly specialized tests like GPQA.
-
Code Capability: Performs well but doesn't achieve absolute dominance; Claude remains competitive in certain tasks.
-
Multimodal Capability: This is Gemini 3's core strength; its native design provides cross-modal understanding capabilities that other models struggle to match.
For ordinary users, these percentage differences may not be noticeable in practical use. More importantly, is the model suitable for your specific scenario? This is why we will discuss practical applications next.
III. Real-world Scenarios: What Can You Do With It?
Benchmark data is only one aspect; more crucially, it's about in which real-world scenarios Gemini 3 can demonstrate its value. Based on its technical characteristics, here are some particularly suitable application areas:
Developer Scenarios
Code Review and Refactoring

Figure 4: Practical Application of Gemini 3—From Code Development to Content Creation, Comprehensive Improvement of Work Efficiency
With the help of millions of context windows, you can directly dump an entire GitHub repository onto Gemini 3, allowing it to:
-
Understand project architecture and code logic
-
Discover potential performance bottlenecks or security risks
-
Provide refactoring suggestions and directly generate code
Full-Stack Development Assistant
In Google AI Studio, Gemini 3 can:
-
Directly generate React/Vue applications based on requirement descriptions
-
Handle front-end, back-end, and database logic simultaneously
-
Automatically write test cases and debug code
API Documentation Analysis
Upload hundreds of pages of technical documentation, and it can:
-
Quickly locate relevant interfaces and parameters
-
Example Call Generation
-
Compare Differences Between Versions
Content Creator Scenarios
Long Document Analysis and Summarization
Researchers and writers can:
-
Upload dozens of papers or reports at once for comparative analysis
-
Extract key viewpoints and data trends
-
Generate structured literature reviews
Multimodal Content Creation
Leveraging powerful multimodal capabilities:
-
Analyze video footage and generate subtitles or scripts
-
Create relevant copy based on image content
-
Understand hand-drawn sketches and generate detailed design solutions
Enterprise Applications
Intelligent Customer Service and Support
Gemini 3 deployed via Vertex AI can:
-
Simultaneously understand user text descriptions and screenshots
-
Access all product documents and historical work orders
-
Provide context-accurate solutions
Data Analysis and Reporting
Agent capabilities enable Gemini 3 to:
-
Automatically collect information from multiple data sources
-
Perform cross-table analysis and data cleaning
-
Generate business reports with visual charts
Knowledge Management
For Enterprise Knowledge Bases:
-
Index and search massive amounts of internal documents
-
Link information across documents
-
Automatically generate knowledge graphs
Education and Learning
Personalized Tutoring
-
Understand students' handwritten problem-solving processes
-
Provide targeted tutoring based on error types
-
Generate practice questions of similar types
Multilingual Learning
-
Analyze pronunciation videos and provide feedback
-
Understand context and correct grammar errors
-
Create immersive learning scenarios
How to Get Gemini 3?
-
Regular Users: Use through AI Mode in the Gemini app and search (requires Google AI Pro or Ultra subscription)
-
Developers: Access through AI Studio, Gemini API, or the Google Antigravity platform
-
Enterprise Users: Deploy through Vertex AI and Gemini Enterprise
IV. Summary: Is Gemini 3 Worth Paying Attention To?
The release of Gemini 3 is undoubtedly a major event in the AI field in 2025. From technical specifications to practical applications, it demonstrates impressive capabilities.
Core Advantages Summary:
-
Superior "memory" thanks to millions of context windows
-
Deep cross-modal understanding achieved through native multimodal design
-
Evolution from "response to execution" brought about by Agent capabilities
-
Leading performance in multiple authoritative benchmarks
Points to Note:
-
Claude remains competitive on certain coding tasks
-
Deep Think mode is not yet fully available and will require a few weeks' wait
-
Some advanced features require a paid subscription (Pro or Ultra)
Who should pay attention to Gemini 3?
If you are a developer, especially those dealing with large codebases or multimodal input projects, Gemini 3's extended context and Agent capabilities will significantly improve development efficiency.
If you are a content creator or researcher, needing to analyze large amounts of documents, videos, or content in multiple media formats, multimodal capabilities and long text processing will be invaluable tools.
If you are a business decision-maker considering integrating AI into your business processes, Gemini 3's enterprise-grade deployment solution and powerful integration capabilities are worth evaluating.
For general users, if you are already using ChatGPT or Claude, you can try the free version of Gemini 3 to experience its multimodal capabilities and deep integration with the Google ecosystem.
The competition in AI has never stopped, and every major release pushes the boundaries of technology forward. The emergence of Gemini 3 proves that Google still possesses strong technical strength and innovation capabilities in this race. As an AI tool navigation site, we will continue to track its actual performance and bring you more in-depth reviews and usage guides.
What are your thoughts on Gemini 3? Feel free to share your experience and opinions in the comments section.
Official X Release:
https://x.com/GeminiApp/status/1990812977818431548?s=20
Usage Address:
Leave your comment
- No comments yet.
Recommended AI Tools
Carefully selected AI tools to improve your work, study, and live efficiency.
Related Articles
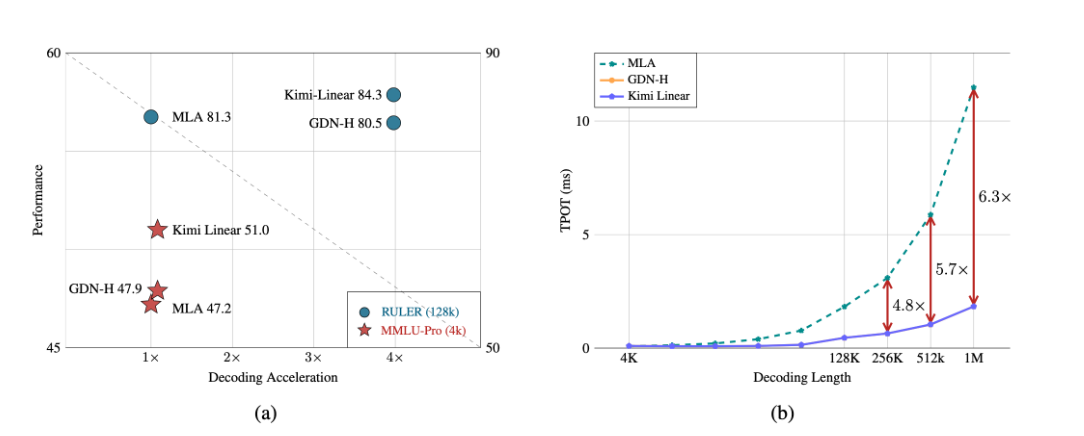
A major breakthrough has been achieved in the core architecture of large-scale models! The release of Kimi Linear marks the first time that linear attention technology has comprehensively surpassed and significantly outperformed the traditional Transformer full-attention model in both performance and efficiency. This "win-win" achievement is expected to significantly reduce the computational barriers and costs for long text processing, complex reasoning, and AI agent applications, potentially changing the competitive landscape of underlying technologies for large-scale models.

Over the past week, the AI community's attention has been drawn to a mysterious model that quietly emerged on the OpenRouter platform—Polaris Alpha. As a direct continuation of yesterday's discussion of the GPT-5.1 leak, this suddenly appearing model brings more technical details and strategic signals worthy of in-depth exploration.

A new paradigm in knowledge acquisition has arrived, this time powered by AI.

Standing at this moment in 2025, when we look back at the development journey of artificial intelligence, we witness how this revolutionary technology has reshaped every aspect of human society. From initial theoretical concepts to today's practical applications, each step forward in AI technology has changed the way we live. Let's revisit this fascinating journey together.