Qwen-AgentWorld: Language World Models for General Agents
TL;DR
Qwen just released Qwen-AgentWorld, a language model trained to simulate agentic environments. Instead of training agents in real environments (slow, expensive, uncontrollable), train a model that can predict what the environment would return for any given action. The model is the environment.
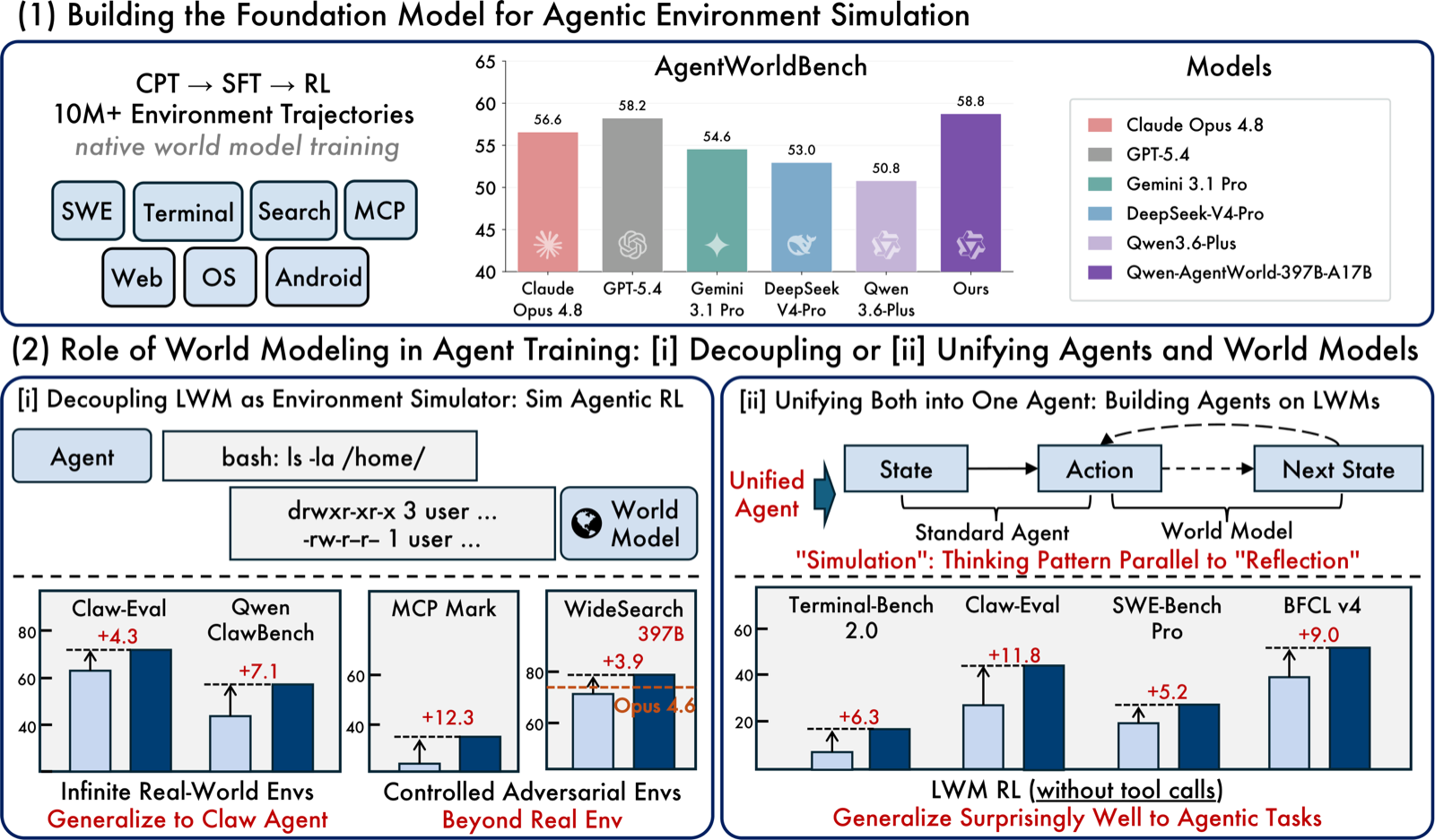
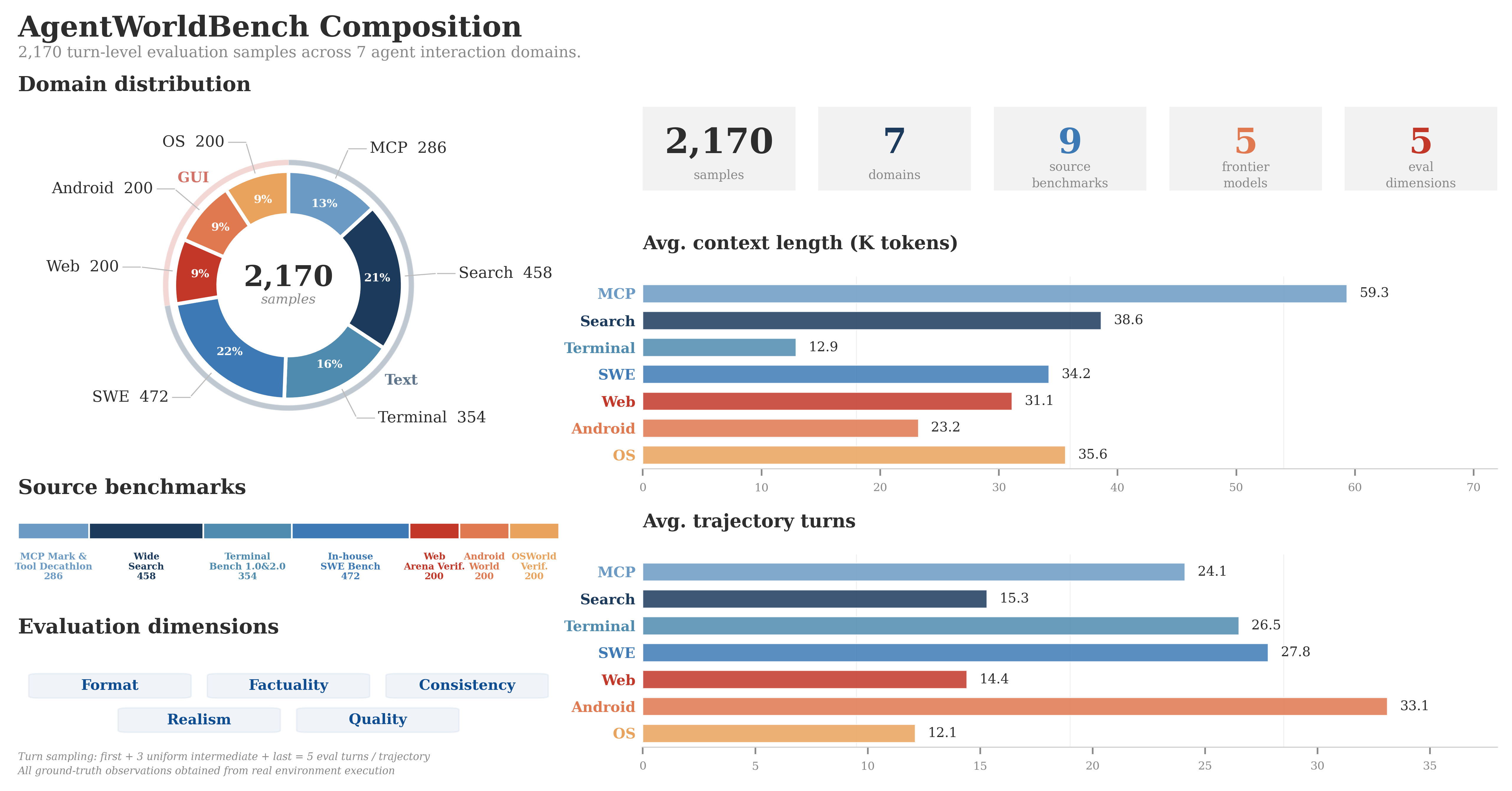
It covers 7 domains in a single model: MCP, Search, Terminal, Android, Web Browser, OS, and SWE.
Model Sizes
- Qwen-AgentWorld-35B-A3B — MoE, 35B total / 3B active, 256K context — open source
- Qwen-AgentWorld-397B-A17B — not open source
Three-Stage Training Pipeline
The paper "Language World Models for General Agents" describes a three-stage process:
- CPT (Continued Pre-Training) — 10M+ real-world interaction trajectories across 7 domains. The model learns state transition dynamics.
- SFT (Supervised Fine-Tuning) — Activates next-state-prediction reasoning via long chain-of-thought.
- RL (Reinforcement Learning) — Hybrid rubric-and-rule reward to sharpen simulation fidelity.
The key difference from prior work: environment modeling is the core training objective from stage one, not a post-hoc add-on. Hence "native world model."
Benchmark Results
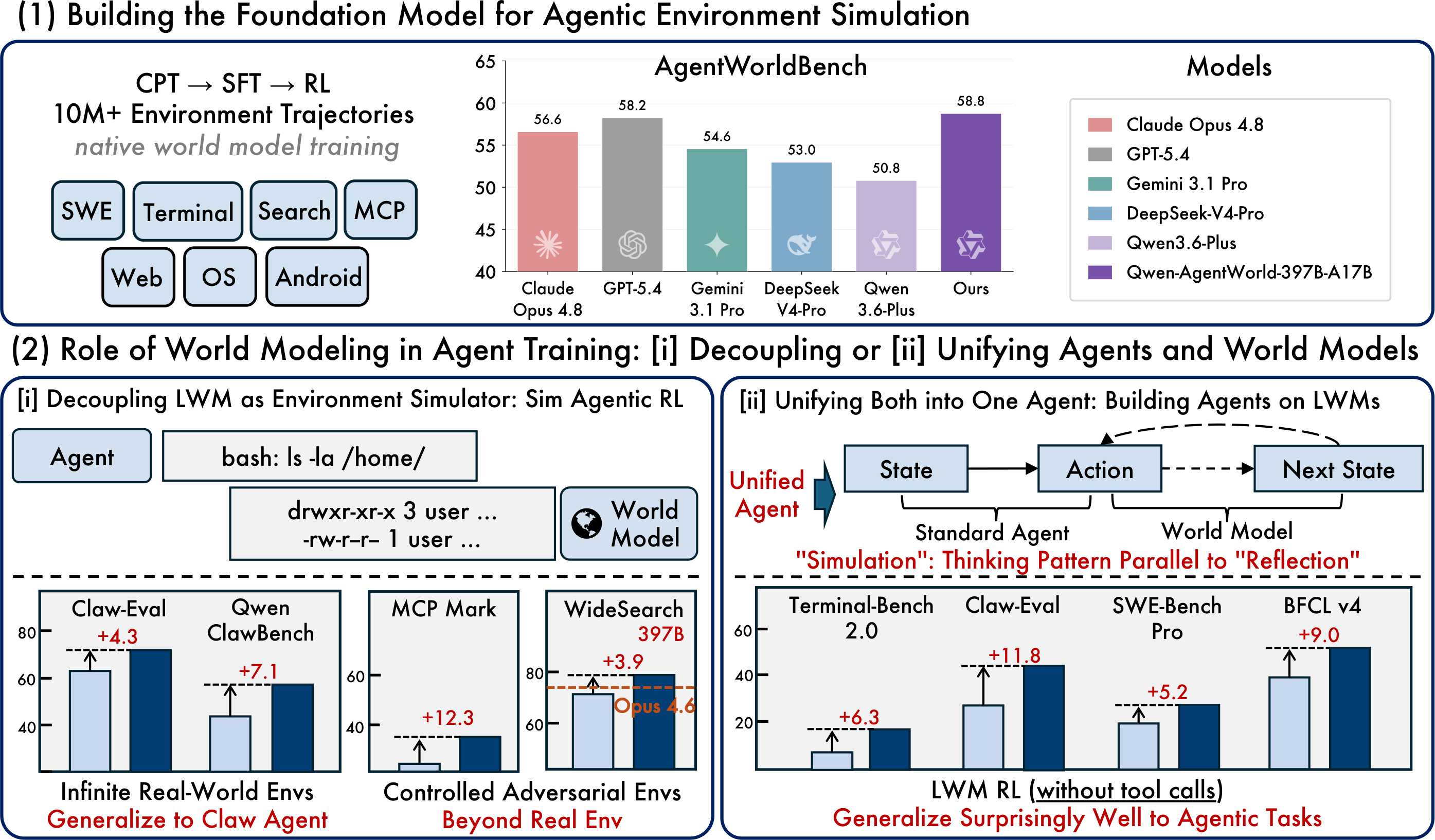
They created AgentWorldBench, spanning 7 domains with data from 5 frontier models.
| Model | Overall |
|---|---|
| Qwen-AgentWorld-397B-A17B | 58.71 |
| GPT-5.4 | 58.25 |
| Claude Opus 4.6 | 57.80 |
| Claude Opus 4.8 | 56.59 |
| Qwen-AgentWorld-35B-A3B | 56.39 |
| Gemini 3.1 Pro | 54.57 |
The 35B-A3B version (3B active parameters) matches Claude Opus 4.8 within 1 point. Without world model training, the same architecture scores only 47.73 — LWM training provides a +8.66 boost.
Key Discovery 1: Simulated Training Beats Real Training
Using Qwen-AgentWorld as a simulated environment for RL actually outperforms training in real environments.
| Metric | Baseline | + Sim RL (397B env) | Delta |
|---|---|---|---|
| Claw-Eval | 65.4 | 69.7 | +4.3 |
| QwenClawBench | 47.9 | 55.0 | +7.1 |
It also supports controllable simulation: inject perturbations, construct fictional worlds, train under harder conditions. Agents trained in fictional search worlds still generalize to real search (F1 +16.29).
Key Discovery 2: Predicting Environments Makes Agents Stronger
LWM warm-up on single-turn, non-agentic trajectories improves downstream agent performance — even on out-of-domain tasks with zero agent-specific fine-tuning.
| Benchmark | Without LWM | With LWM | Delta |
|---|---|---|---|
| Terminal-Bench 2.0 | 33.25 | 39.55 | +6.30 |
| SWE-Bench Verified | 64.47 | 67.86 | +3.39 |
| WideSearch F1 (OOD) | 33.38 | 46.17 | +12.79 |
| Claw-Eval (OOD) | 53.60 | 64.88 | +11.28 |
| BFCL v4 (OOD) | 62.29 | 71.25 | +8.96 |
Why This Matters
This is the AlphaGo approach applied to agents: self-play in a simulated world, without needing real environments. If it scales, agent training costs drop dramatically — one model replaces thousands of browser instances, API calls, and Docker containers.
The open question: how well does the simulation generalize? The gap between simulated and real environments still exists. But as a proof of concept, this is one of the most interesting agent research directions of 2026.
Resources
Leave your comment
- No comments yet.
Recommended AI Tools
Carefully selected AI tools to improve your work, study, and live efficiency.
Related Articles
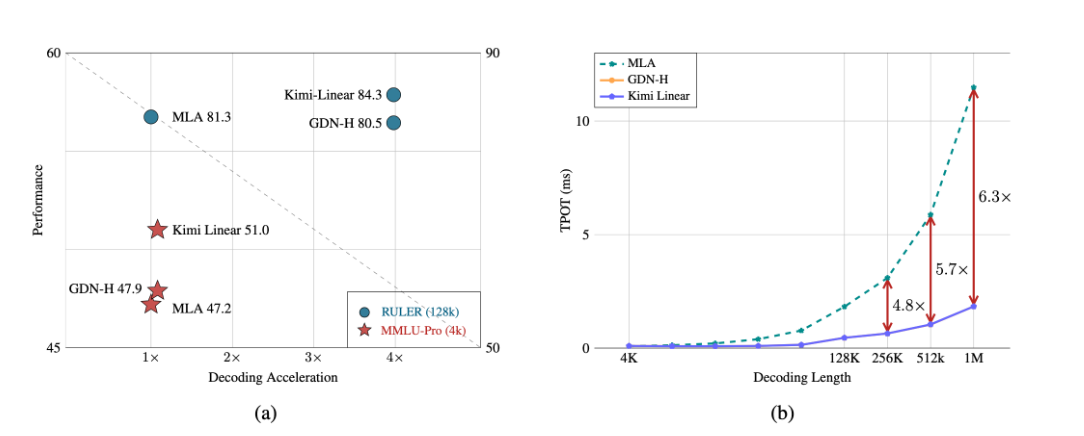
A major breakthrough has been achieved in the core architecture of large-scale models! The release of Kimi Linear marks the first time that linear attention technology has comprehensively surpassed and significantly outperformed the traditional Transformer full-attention model in both performance and efficiency. This "win-win" achievement is expected to significantly reduce the computational barriers and costs for long text processing, complex reasoning, and AI agent applications, potentially changing the competitive landscape of underlying technologies for large-scale models.

Over the past week, the AI community's attention has been drawn to a mysterious model that quietly emerged on the OpenRouter platform—Polaris Alpha. As a direct continuation of yesterday's discussion of the GPT-5.1 leak, this suddenly appearing model brings more technical details and strategic signals worthy of in-depth exploration.

A new paradigm in knowledge acquisition has arrived, this time powered by AI.

Standing at this moment in 2025, when we look back at the development journey of artificial intelligence, we witness how this revolutionary technology has reshaped every aspect of human society. From initial theoretical concepts to today's practical applications, each step forward in AI technology has changed the way we live. Let's revisit this fascinating journey together.